
사전지식
Face Detection with cascade Object Detector
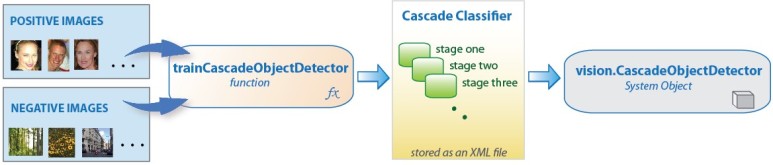
그림1.에서 머신러닝의 학습데이터로써 사람의 얼굴이 포함된 Positice lmage와 얼굴이 포함되지 않은 Negative Image를 사용하며 Positive Image에서 사람의 얼굴을 ROI(Region Of Interest)로 표시한다. 다음으로 영상에서 특징을 추출하는 작업을 수행하는데, 사람 얼굴의 특징을 추출하기 위해서는 Haar-like feature나 LBP(Local Binary Patters)등이 자주 사용된다. 그리고 분류기를 훈련시키는 작업이 이어지게 된다. Cascade of Classifier라는 분류가 한 번에 결정되는 것이 아니라 여러단계(Cascade)의 분류과정을 거치게 된다.
출처:https://blog.naver.com/matlablove/220928458225
sub window : 트레이닝시 Positive 혹은 Negative 샘플을 뜻함
Adaboost : Adaptive(적응할 수 있는)+Boosting
여기서 Boosting이란 "조금 성능이 떨어지는 Classifier들을 조합하여 성능이 높은 Classifier를 만든다"
어떻게? Adaptive하게
Abstract
이 논문은 빠른 이미지 처리와 높은 detection rate를 성취할 수 있는 visual object detection을 위한 머신러닝 접근법에대해 설명한다. 이 일은 3가지 핵심 contribution에의해 구분된다.
첫번째는 특징들을 매우 빠르게 계산되게 해주는 "Integral Image"라 불리는 새로운 이미지 묘사의 도입이다.
두번째는 AdaBoost에 기반한 learning algorithm이다. 이것은 큰 집합에서 소수의 중요한 visual feature를 선택하며 매우 효율적인 classifier을 산출한다.
세번째로는 "cascade"에서 점점 더 복잡한 classifiers를 결합하는 방법이다. 이것은 이미지의 background 영역이 빠르게 버려지게 하는 동시에 유망한 객체와 같은 영역에 더 많은 계산을 할 수 있도록 한다.
cascade는 객체를 명확하게 focus하는 mechanism으로 볼수 있다. 이것은 이전 접근법과는 다르게 버려진 영역이 객체의 interest(사람 얼굴이 있을)를 포함할 가능성이 낮다는 통계적 guarantees를 제공해준다.
face detection의 domain에서 시스템은 최고의 이전 시스템과는 비교되는 detection rate를 산출한다.
real-time application에 사용되는 detector은 피부색 감지 또는 이미지 차이에 의존하지않고 초당 15 frame으로 작동한다.
2. Features
object detection 절차는 단순한 feature의 값에 기반하여 이미지를 분류한다. pixel을 직접 사용하는 것보다 feture을 사용하는 동기가 많다. 가장 흔한 이유는 feature이 훈련 data의 특정 양을 사용하여 학습하기 어려운 ad-hoc(임시) 도메인 지식을 인코딩하는 역할을 할 수 있기 때문이다. 두번째 이유가 있는데 시스템에 기반한 feature은 pixel 기반 시스템보다 훨씬 빠르게 동작한다.
사용된 단순한 feature은 Papageogiou에 의해 사용된 Haar basis function을 연상시킨다.
더 구체적으로, 우리는 3가지 종류의 feature을 사용한다. 두개의 직사각형 feature의 값은 두개의 직사각형 영역 내에서 pixel의 합 사이의 차이다. 이 영역(검정부분과 흰색부분)은 같은 사이즈와 모양를 가지며 수평 또는 수직적으로 인접하다.
직사각형의 feture 값은 Figure1과 Figure3를 같이 보면 영상에서 검정부분과 흰색부분에 해당하는 밝기 값을 빼서 임계값 이상인 것을 찾는것이다. 물론 입력영상에서 A,B,C,D와 같은 Sub-Window를 Sliding시켜 탐색한다.
세개의 직사각형 feature은 바깥의 두개 직사각형 합에서 가운데 직사각형을 빼서 계산한다.

Haar basis와는 달리 직사각형 feature의 집합은 overcomplete점에 유의하자.
overcomplete란?
A complete basis has no linear dependence between basis elements and has the same number of elements as the image space, in this case 576. The full set of 180,000 thousand features is many times over-complete.
2.1 Integral Image
직사각형 feature은 integral image라고 불리는 이미지에 대한 중간 표현을 사용하여 매우 빠르게 계산할 수 있다.
위치x,y의 integral image에는 x,y의 왼쪽과 위에있는 pixel의 합이 포함되어있다.
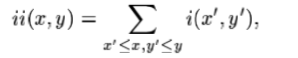
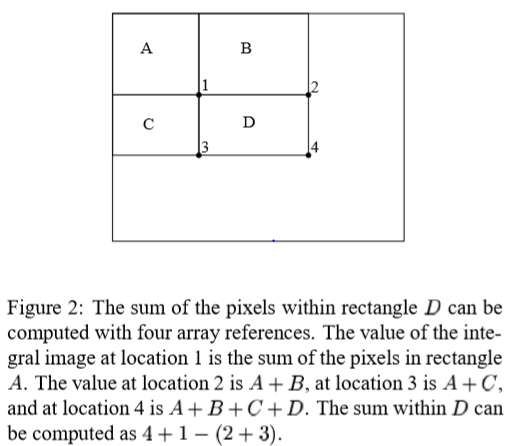
integral image를 사용해서 모든 직사각형 합을 4개의 배열 참조로 계산할 수 있다.(Figure 2)
분명히 두개의 직사각형 합계의 차이는 8개의 참조로 계산할 수 있다.
2개의 직사각형은 6개의 참조로 계산하고 3개의 직사각형은 8개, 4개의 직사각형은 9개의 참조로 계산된다.
궁금한점)
왜 두개의 직사각형은 6개의 참조로 계산하고 3개는 8개인가??
영상에서 window내의 검정부분과 흰색부분의 밝기값을 계속 더하고 빼는 것은 상당히 비효율적이다.
그래서 Integral image방법을 사용한다.
B의 밝기합=2번지점-1번지점
C의 밝기합=3번지점-1번지점
D의 밝기합=4번지점-2번지점-3번지접+1번지점
결과적으로 원점으로부터 각 픽셀(x,y)까지의 사각형 밝기값 총합을 저장하고 있으면 위와 같이 간단히 영역별 밝기값 덧셋뺄셈으로 손쉽게 Feature를 적용할 수 있다.
3. Learning Classification Functions
feature 집합과 positive(사람의 얼굴이 포함된) 및 negative(얼굴이 포함되지 않은)의 이미지 training 집합을 고려할때, classification function을 학습하는데 기계학습 접근법을 얼마든지 사용할 수 있다. 우리 시스템에서는 AdaBoost의 변형이 작은 features의 집합을 선택하고 classifier를 훈련하는데 사용된다.
원래 형태에서 AdaBoost 학습 알고리즘은 simple(때때로 weak라고 불리는) 학습 알고리즘의 classification 성능을 높이는데 사용된다.
주요 통찰력은 일반화 수행이 예제의 여백과 관련이 있으며 AdaBoost는 큰 여백을 빠르게 달성한다.
pixel의 수보다 큰 rectangle feature은 매우 효율적으로 계산할 수 있지만, 전체 세트의 계산은 엄청나게 비싸다. 실험에 의해 얻어진 우리의 가정은 매우 적은 수의 이러한 feature들이 결합되어 효과적인 classifier를 형성할 수 있다는 것이다. 주요 과제는 이들의 feature을 파악하는 것이다.
이 목표를 지원하기 위해, weak 학습 알고리즘은 positive와 negative example를 가장 잘 구분하는 single 직사각형 featrue 을 선택하도록 설계된다. 각각의 feature을 위해서 weak learner는 최소 개수의 예시가 잘못 분류되도록 최적의 threshold(임계값) classification funtion을 결정짓는다.(즉, weak lerner는 분류를 잘하기 위해 threshold를 결정짓는다.)
그러므로 weak classifier( h(x) )는 featrue(f ), threshold(θ)와 parity(p)(부등식 기호의 방향을 나타내는)로 구성된다.
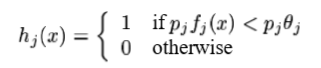
3.2 Learning Results
처음 실험은 200 feature로 구성된 frontal face classifier는 95% detection rate를 낸다는 것을 입증했다. 이 결과는 설득력이 있지만 많은 실제 작업에는 적합하지않다. 계산 측면에서 이 classifier는 매우 빠르지만 불행히도 detection 성능을 향상시키기 위한 가장 간단한 기법은 classifier에 feature를 추가햐여 계산 시간을 직접적으로 증가시킨다.
face detection 과제의 경우, AdaBoost가 선택한 초기 직사각형 feature은 의미있고 쉽게 해석할 수 있다. 선택된 첫번째 feature는 눈의 구역은 종종 코과 뺨의 구역보다 어둡다는 속성에 초점을 맞춘 것 같다.(Figure 3) 이 feature은 sub-window detection에 비해 상대적으로 크며, 얼굴의 크기와 위치에 다소 둔감해야만한다. 선택된 두번째 feature는 눈이 미간보다 더 어둡다는 특성에 달려있다.

4.The Attentional Cascade
이 절은 계산 시간을 줄여주면서 detection 성능을 높여주는 cascade classifier 구성을 위한 알고리즘을 설명한다. 핵심 통찰력은 거의 모든 positive instance를 detect하는 동안 많은 negative sub-window을 거부하는 더 작고, 따라서 더 효율적이고, 강화된 분류자(boosted classifier)를 구성할 수 있다는 것이다.(예를 들어 강화된 classifier의 threshold는 조정될수있어서 false negative rate는 0에 가깝다.) 더 복잡한 classifier가 낮은 false positive rate를 달성하도록 요구되기 전에 더 단순한 classifier는 sub-window 대다수를 거부하는데 사용된다.
detection 과정의 전반적인 형태는 우리가 cascade라고 불리는 degenerate decision tree이다.(Figure 4) 첫번째 classifier로부터 positive result는 매우 높은 detection rate를 달성하도록 조정된 두번째 classifier의 evaluation을 촉진한다. 두번째 classifier로부터 positive 결과는 세번째 classifier를 촉진시킨다. 어느 시점에서든 negative 결과가 나오면 sub-window의 즉각적인 거부로 이어진다.
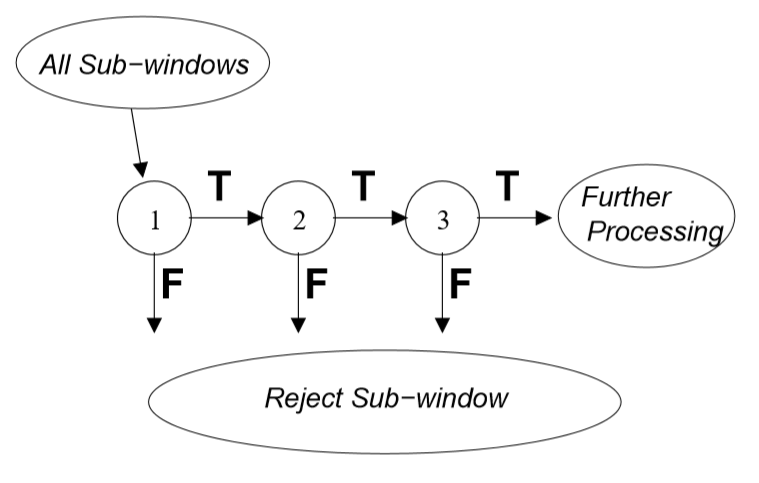
Boosting 된 강분류기를 입력영상에 Sliding시켜서 Object Detection을 한다.
그런데 연산이 복잡한 강분류기를 모든 영역에 적용시키는것은 비효율적이다.
다시말해 Object는 입력영상의 일부분일 뿐 모든 부분에 퍼져있지 않다는 가정을 한다.
(예, 단체사진에서 사람의 얼굴이 사진에서 차지하는 비율은 극히 일부분이다.)
그래서
Object의 특성은 유지하되 아닐수도 있는 확률이 조금 높은, 간단한 강분류기를 Sliding시키고
통과시, Object가 아닐수도 있는 확률이 더 낮은, 조금은 더 강한 강분류기를 Sliding시키고
불통시, 해당 Sub-Window를 다음 Sliding시 건너뛰는 방식으로
Object가 아닌 부분을 줄여나가고 Object가 맞을 것 같은 부분에 더 강한 분류기를 통과시켜
최종적인 결과를 찾아가는 방식이다.
예를 들어,
시험점수 100점인사람을 찾는데 5가지 질문을 할수 있다면,
1. 50점 넘니?
2. 70점 넘니? -> 50점 이상인 사람에게만 질문함
3. 80점 넘니? -> 70점 이상인 사람에게만 질문함
4. 90점 넘니? -> 80점 이상인 사람에게만 질문함
5. 99점 넘니? -> 90점 이상인 사람에게만 질문함
4.1. Training a Cascade of Classifiers
cascade traning 처리과정은 trade-off 의 두 타입과 연관되어있다. 더 많은 featrue을 가진 classifier의 대부분의 경우에는 더 높은 detection rate와 더 낮은 false positive rate를 달성할것이다. 동시에 계산시간을 더 요구한다. 원칙적으로 평가된(evaluated) feature의 예상 개수를 최소화하기 위해 i) classifier 단계 수 ii) 각 단계의 featrue수 iii) 각 단계의 threshold가 서로 (trade-off)되는 최적화 프레임워크를 정의할 수 있다. 불행하게도 최적화 프레임워크를 정의하는데 어렵다.
여기서 trade의 두 타입은 아래에 나오는 false positive rate와 detection rate이다.
cascade의 각 단계는 false positive rate와 detection rate를 감소시킨다. false positive 최소 감소와 detect 최대 감소를 위해 target(대상)이 선택된다. 각 단계는 target detection와 false positive rate가 만날때까지 featrue을 추가함으로써 훈련된다.
4.2.Detector Cascade Discussion
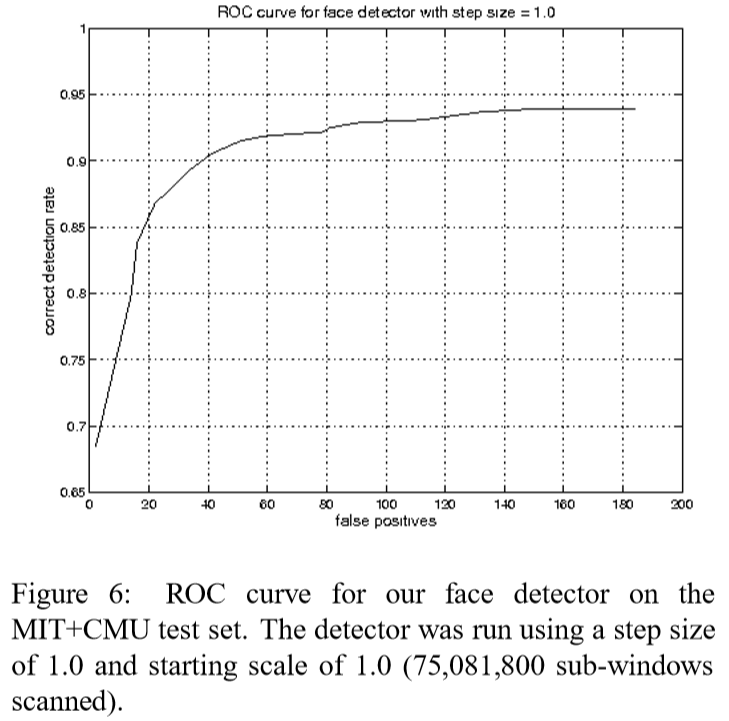
완전한 face detection cascade는 6000 feature를 가진 38단계를 가진다. 그럼에도 불구하고 cascade 구조는 빠른 평균 detection times 결과를 가진다. 507개 얼굴과 7500만 개의 sub window를 포함하는 어려운 dataset에서 얼굴은 sub-window당 평균 10개의 feature evalution을 사용하여 검출된다. 이 시스템은 Rowley 등이 구축한 에 검출 시스템의 구현보다 약 15배 빠르다.
5. Result
Speed of the Final Detector
cascade detector의 속도는 스캔된 sub-window당 evaluate된 feature의 수와 직접적으로 관련되어있다. MIT+CMU test set에서 평가되며, sub-window당 총 6061개 중 평균 10개의 feature이 평가된다(evaluate). sub window의 대다수는 첫번째 두번째 층에 의해 거부되기 때문에 가능하다. 700 Mhz Pentium III processor에서 face detector는 약 0.067초 내 384 X 288 pixel image를 처리할 수 있다. 이것은 대략적으로 Rowley-Buluja-Kanade detector보다 15배 빠르고 Schneiderman-Kanade detector보다 600배 빠르다.
Image Processing
트레이닝에 사용되는 모든 sub-window는 다른 조명 조건의 영향을 최소화하기 위해 변화량을 정규화되었다. 그러므로 정규화는 모든 detection에서 필수적이다. image sub-window의 변화량은 integral image 쌍을 사용해서 빠르게 계산할 수 있다.
Scanning the Detector
final detector는 여러 scale과 location에서 이미지의 전체에서 스캔된다. Scaling은 오히려 이미지를 scale하는것보다 detector스스로 scaling한다. 동일한 비용으로 어떤 규모에서도 feature을 평가할 수 있기 때문에 이 과정은 타당한다.
좋은 결과는 1.25의 factor scale set을 사용해서 얻어진다.
detector은 또한 location을 가로질러 스캔된다. 그 다음의 location은 window를 몇 pixel 이동하면 얻을 수 있다.
A simple voting scheme to further improve results
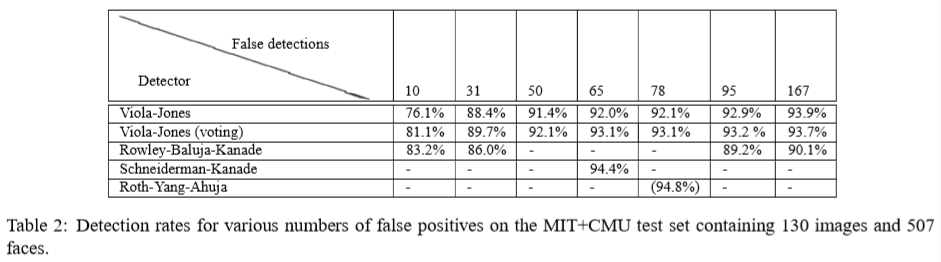
table 2에서 우리는 또한 3개의 detector(위에서 설명한 38개 layer 1과 유사하게 훈련된 검출기 2개)를 실행하고 3개의 detector의 다수표를 출력한 결과도 보여준다. 이것은 false positive를 감소시킬 뿐만아니라 detection rate를 향상시킨다. 만약 detector이 더 독립적이라면 개선은 더 클것이다. 오류의 상관관계는 최상의 single detector에 비해 다소 개선되는 결과를 초래한다.
6. Conclusion
우리는 높은 detection 정확도를 가지면서 계산 시간을 최소화하는 object detection을 위한 접근법을 제시해 왔다.
이 접근법은 이전 접근법보다 대략 15 더 빠른 얼굴 detection 시스템을 구성하기 위해 사용된다.
이 논문은 상당히 일반적인 새로운 알고리즘 ,표현 및 통찰력을 종합하여 컴퓨터 비젼과 이미지 처리에서 더 광범위한 응용을 할 수 있다.
마지막으로 이 논문은 널리 학습된 어려운 face detection dataset에 대한 상세한 실험을 제시한다. 이 dataset은 넓은 범위의 조건(illumination,scale,pose,camera variation)들을 가진 얼굴을 포함한다. 이러한 크고 복잡한 dataset에대한 실험은 어렵고 시간이 걸린다. 그럼에도 불구하고 이러한 조건하에 시스템은 취약하거나 단일 조건으로 제한되지않는다.
더 중요한것은 dataset에서 도출된 결론은 실험적 artifacts일 가능성이 낮다.

느낀점: 단순히 처리 속도가 빠를 뿐만 아니라 dataset의 조건이 어려움에도 불구하고 높은 정확도를 가질 수 있다는 것에 인상깊었다.
그 이유는 cascade classifier을 false positive rate와 detection rate이 만날때까지(이 둘은 trade off) 훈련시켜서 negative sub-window를 거부시켜 속도를 빠르게 하기 때문이다. cascade classifier를 새로 알아가면서 face detection에 필요한 감지기라는 것을 알았다.
Adaboost에 기반한 learning algorithm에 대한 나의 정리:
Adaboost은 분류기(classifier)를 훈련시키는데 이용(더 좋은 분류를 위해)하는데 그 방법은 약분류기에 매번 다른 가중치를 업데이트 시켜서 강분류기가 되도록 하는것 같다.
논문에서는 결국 강분류기를 사용하면 비효율적이기 때문에 weak 학습 알고리즘을 사용해서 작은 feature 집합을 선택하도록 threshold을 사용한 funtion을 제안
'Programmer > Deep Learning' 카테고리의 다른 글
| YOLO 튜토리얼 2. Creating the layers of the network architecture (0) | 2020.04.26 |
|---|---|
| YOLO 튜토리얼 1.YOLO 란? (0) | 2020.04.26 |
| [논문리뷰] An Overview Of Face Liveness Detection 2 (0) | 2020.04.19 |
| [논문리뷰] An Overview of Face Liveness Detection1 (0) | 2020.04.18 |
| Precision(정밀도) , Recall(재현율) , Accuracy(정확도) , FLOPS (0) | 2020.04.08 |