
해시(Hash)란?
데이터를 다루는 기법 중 하나이며, 키(key)와 값(value)으로 매핑되는 과정 자체를 해싱(Hashing)이라고 한다.
해싱이 왜 필요할까?
선형 탐색 또는 이진 탐색은 찾는 키가 자료구조에 들어있는지 반복적 비교가 필요
-> 아무리 빨라도 O(logn)
->더 빠른 알고리즘 필요
->O(1)을 보장하는 탐색 예로는 키를 그대로 1차원 배열의 인덱스로 사용
->하지만 단순히 키를 배열의 인덱스로 그대로 사용하면 메모리 낭비가 심해질 수 있음.
∴ O(1) 시간 안에 탐색을 끝내면서 키를 변환하여 배열의 인덱스로 사용하는 방법인 "해싱"
키(key)
고유한 값이며, 해시 함수의 input이 된다. 다양한 길이의 값이 될 수 있다. 이 상태로 최종 저장소에 저장이 되면 다양한 길이 만큼의 저장소를 구성해 두어야 하기 때문에 해시 함수로 값을 바꾸어 저장이 되어야 공간의 효율성을 추구할 수 있다.
값(Value)
저장소(bucket,slot)에 최종적으로 저장되는 값으로 키와 매칭되어 저장, 삭제 ,검색, 접근이 가능해야 한다.
해시함수(Hash Function)
데이터를 효율적으로 관리하기 위해서 임의의 길이의 데이터를 고정된 길이의 데이터로 매핑하는 함수이다.
해시 테이블 (Hash Table)
키(key)와 값(value)이 하나의 쌍을 이루는 데이터 구조이다. 즉, 키와 배열의 인덱스를 이용하여 키를 저장하는 자료구조이다. 해시 테이블은 해시 맵, 맵, 딕셔너리, 연관 배열이라는 이름으로 알려져 있다.
해시 테이블은 키를 해시 함수(hash funtion)로 계산하여 그 값을 배열의 인덱스로 사용한다.
이때, 해시 함수에 의해 반환된 데이터의 고유 숫자 값을 해시값 또는 해시코드라고 한다. 즉,key값을 해시 함수를 통해서 배열의 인덱스로 바꿔주고, 그 자리에 데이터를 저장한다.
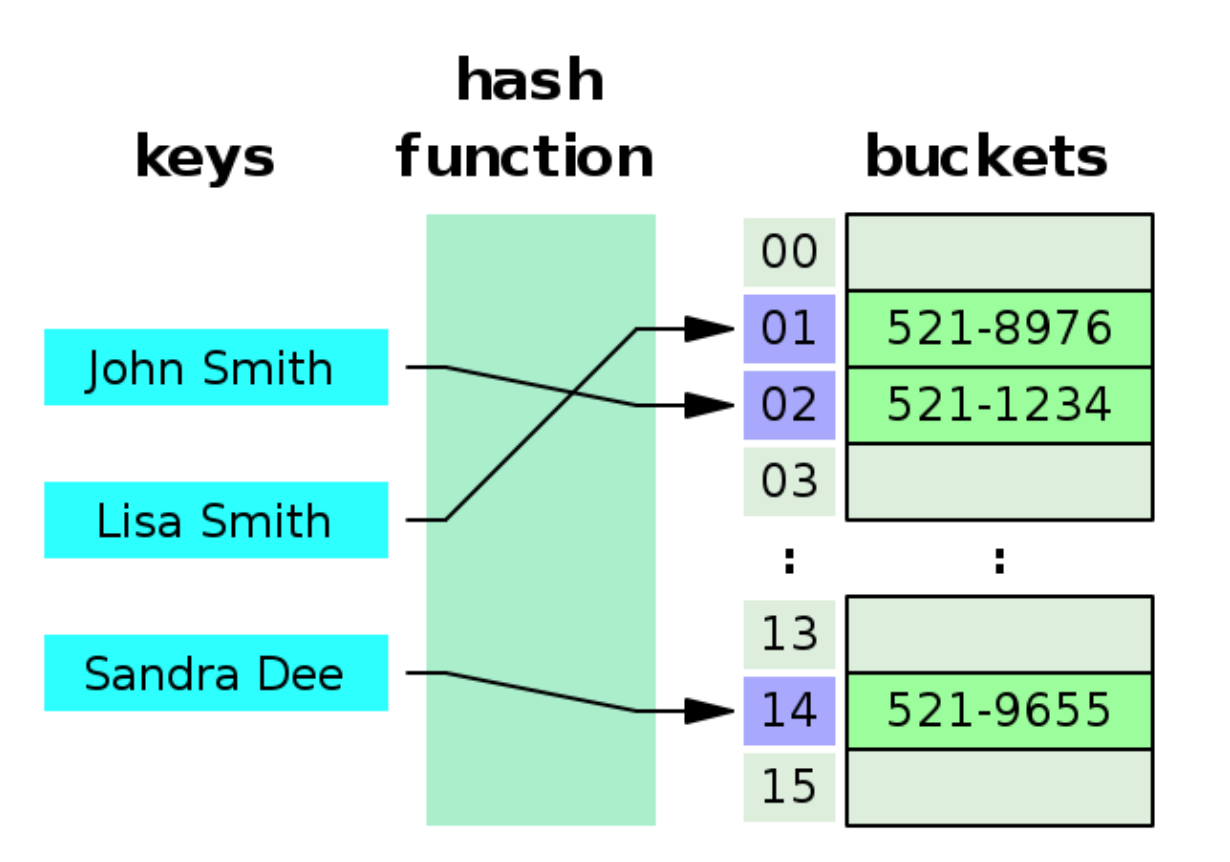
충돌 문제(Hash Collision)
- 무한한 값(해시테이블에서 key)을 유한한 값(해시테이블에서 hash)으로 표현하면서 서로 다른 두 개 이상의 유한한 값이 동일한 출력값을 가지게 된다.
- 서로 다른 키들이 동일한 해시값을 가질 때 충돌(Collision) 발생
-충돌이 많아질수록 탐색의 시간 복잡도가 O(1)에서 O(n)에 가까워지기 때문에 충돌을 줄여주는 해시 함수를 사용하는 것이 좋다.

충돌 해결법
1) 분리 연결법(Separating Chaining)
동일한 버킷(저장소)의 데이터에 대해 자료구조( Linked List, Tree(Red-Black Tree) )를 활용해 추가 메모리를 사용하여 다음 데이터의 주소를 저장하는 것이다.
다음은 Linked list를 사용한 것이다. 인덱스가 충돌이 날 때, 인덱스가 가리키고 있는 linked list에 노드를 추가하여 값을 삽입한다.
데이터를 탐색할 때는 키에 대한 인덱스가 가리키고 있는 Linked list를 선형 검색하여, 해당 키에 대한 데이터를 반환한다.
삭제하는 것도 비슷하게, 키에 대한 인덱스가 가리키고 있는 Linked list에서, 그 노드를 삭제한다.
Separate changing 방식은 Linked List 구조를 사용하고 있기 때문에, 추가할 수 있는 데이타 수의 제약이 작다.
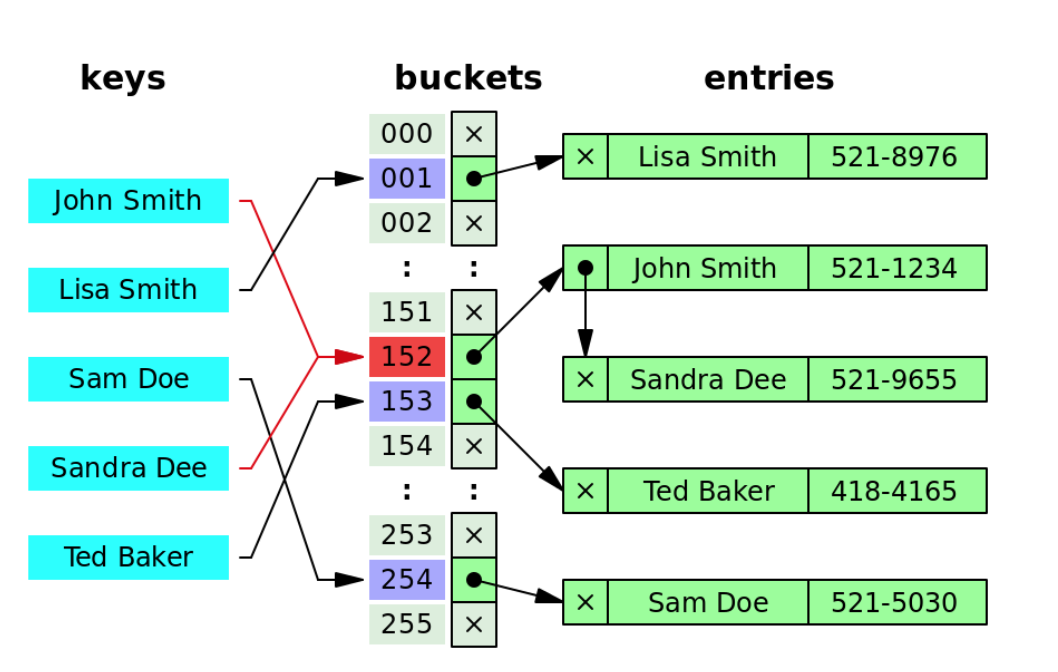
2) 개방 주소법(Open Addressing)
해시테이블 전체를 열린 공간으로 가정하고 충돌된 키를 일정한 방식에 따라서 찾아낸 빈공간에 저장
-대표적인 개방주소방식
- 선형조사(Linear Probing) : 현재 버킷 index로부터 고정폭 만큼씩 이동하여 순차적으로 검색해 비어 있는 버킷에 데이터를 저장한다.
- 이차조사(Quadratic Probing) : 해시의 저장순서 폭을 제곱으로 저장하는 방식이다. 예를 들어 처음 충돌이 발생한 경우에는 1만큼 이동하고 그 다음 계속 충돌이 발생하면 2^2, 3^2칸씩 옮기는 방식이다.
- 이중해싱(Double Hashing) : 2개의 해시함수를 사용해 해시된 값을 한번 더 해싱하여 규칙성을 없애버리는 방식이다. 해시된 값을 한번 더 해싱하여 새로운 주소를 할당하기 때문에 다른 방법들보다 많은 연산을 하게 된다.
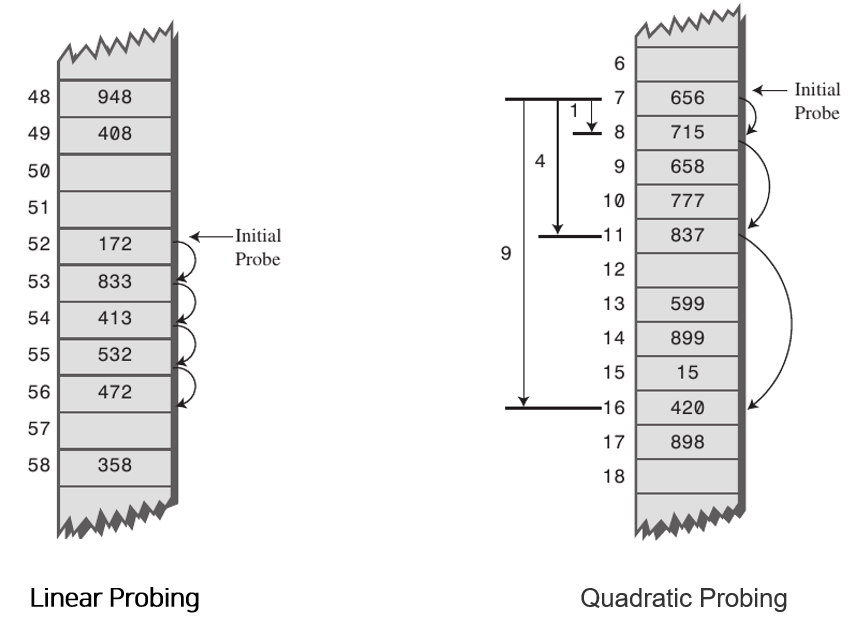
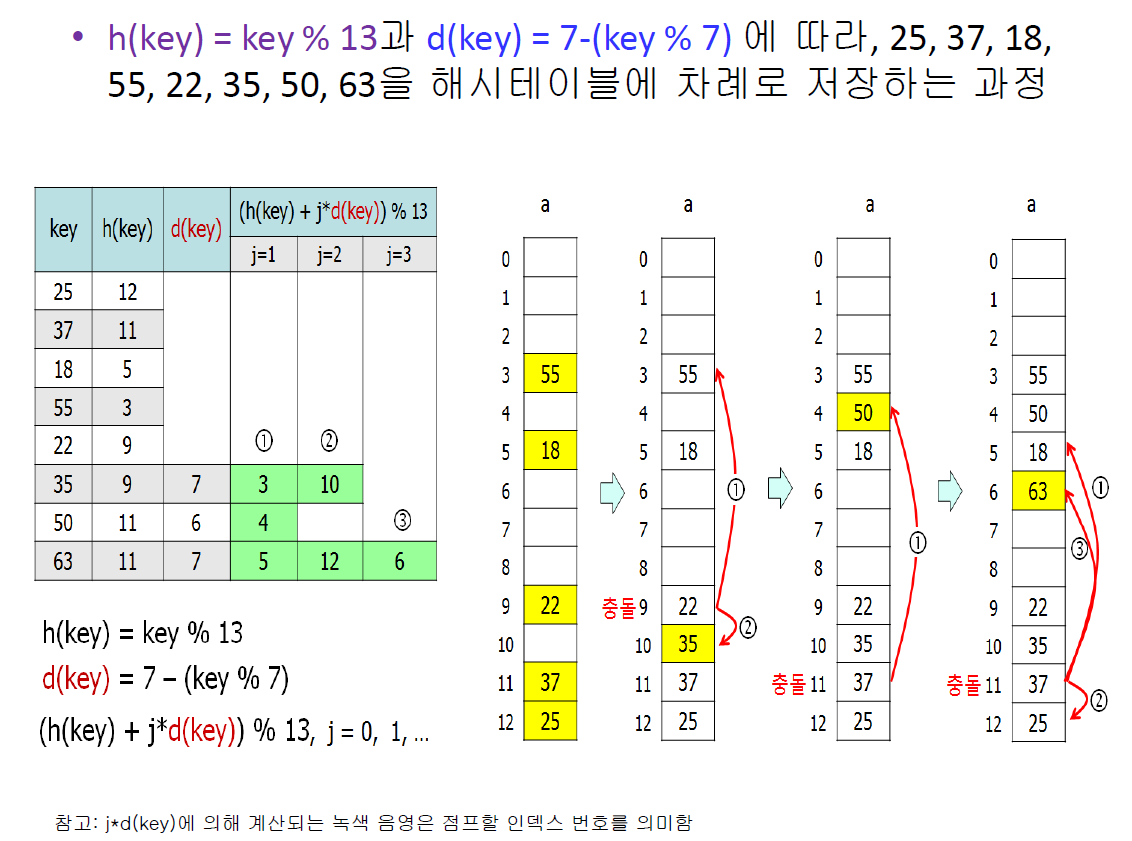
해시 테이블의 성능
-키 값이 배열의 인덱스로 변환되기 때문에 탐색,저장,삭제가 빠르다. 평균 시간 복잡도가 O(1)이다.
-평균 시작 복잡도인 이유는 collision 때문이다.
| 평균적인 경우 | 최악의 경우 | |
| 탐색 | O(1) | O(N) |
| 삽입 | O(1) | O(N) |
| 삭제 | O(1) | O(N) |
관련 포스팅
2021.06.30 - [Algorithm/자료구조] - [Java] Hash Map / Hash Table / Tree Map
[Java] Hash Map / Hash Table / Tree Map
HashMap 클래스 HashMap 클래스는 Map 컬렉션 클래스에서 가장 많이 사용되는 클래스 중 하나이다. JDK 1.2부터 제공된 HashMap 클래스는 해시 알고리즘(hash algorithm)을 사용하여 검색 속도가 매우 빠르다.
hohodu.tistory.com
참고 및 출처
https://mangkyu.tistory.com/102
[자료구조] 해시테이블(HashTable)이란?
1. 해시테이블(HashTable)이란? [ HashTable(해시테이블)이란? ] 해시 테이블은 (Key, Value)로 데이터를 저장하는 자료구조 중 하나로 빠르게 데이터를 검색할 수 있는 자료구조이다. 해시 테이블이 빠른
mangkyu.tistory.com
Hash, Hashing, Hash Table(해시, 해싱 해시테이블) 자료구조의 이해
0_HJVxQPQ-eW0Exx7M.jpeg DATA들이 사용하기 쉽게 정리되어 있다. 자료구조는 도대체 무엇일까? 자료구조(Data-Structure)는 데이터들의 모임, 관계, 함수, 명령 등의 집합을 의미한다. 더 쉽게 표현하자면, 1)
velog.io
'Algorithm > 자료구조' 카테고리의 다른 글
| [자료구조] Union Find (0) | 2021.03.25 |
|---|---|
| [자료구조] 탐색(search) (0) | 2021.03.02 |
| [자료구조] DFS와 BFS (0) | 2021.02.24 |
| [자료구조] 그래프 (0) | 2021.02.24 |
| [자료구조] 동적 계획 (DP : Dynamic Programming) (0) | 2021.02.12 |
해시(Hash)란?
데이터를 다루는 기법 중 하나이며, 키(key)와 값(value)으로 매핑되는 과정 자체를 해싱(Hashing)이라고 한다.
해싱이 왜 필요할까?
선형 탐색 또는 이진 탐색은 찾는 키가 자료구조에 들어있는지 반복적 비교가 필요
-> 아무리 빨라도 O(logn)
->더 빠른 알고리즘 필요
->O(1)을 보장하는 탐색 예로는 키를 그대로 1차원 배열의 인덱스로 사용
->하지만 단순히 키를 배열의 인덱스로 그대로 사용하면 메모리 낭비가 심해질 수 있음.
∴ O(1) 시간 안에 탐색을 끝내면서 키를 변환하여 배열의 인덱스로 사용하는 방법인 "해싱"
키(key)
고유한 값이며, 해시 함수의 input이 된다. 다양한 길이의 값이 될 수 있다. 이 상태로 최종 저장소에 저장이 되면 다양한 길이 만큼의 저장소를 구성해 두어야 하기 때문에 해시 함수로 값을 바꾸어 저장이 되어야 공간의 효율성을 추구할 수 있다.
값(Value)
저장소(bucket,slot)에 최종적으로 저장되는 값으로 키와 매칭되어 저장, 삭제 ,검색, 접근이 가능해야 한다.
해시함수(Hash Function)
데이터를 효율적으로 관리하기 위해서 임의의 길이의 데이터를 고정된 길이의 데이터로 매핑하는 함수이다.
해시 테이블 (Hash Table)
키(key)와 값(value)이 하나의 쌍을 이루는 데이터 구조이다. 즉, 키와 배열의 인덱스를 이용하여 키를 저장하는 자료구조이다. 해시 테이블은 해시 맵, 맵, 딕셔너리, 연관 배열이라는 이름으로 알려져 있다.
해시 테이블은 키를 해시 함수(hash funtion)로 계산하여 그 값을 배열의 인덱스로 사용한다.
이때, 해시 함수에 의해 반환된 데이터의 고유 숫자 값을 해시값 또는 해시코드라고 한다. 즉,key값을 해시 함수를 통해서 배열의 인덱스로 바꿔주고, 그 자리에 데이터를 저장한다.
충돌 문제(Hash Collision)
- 무한한 값(해시테이블에서 key)을 유한한 값(해시테이블에서 hash)으로 표현하면서 서로 다른 두 개 이상의 유한한 값이 동일한 출력값을 가지게 된다.
- 서로 다른 키들이 동일한 해시값을 가질 때 충돌(Collision) 발생
-충돌이 많아질수록 탐색의 시간 복잡도가 O(1)에서 O(n)에 가까워지기 때문에 충돌을 줄여주는 해시 함수를 사용하는 것이 좋다.
충돌 해결법
1) 분리 연결법(Separating Chaining)
동일한 버킷(저장소)의 데이터에 대해 자료구조( Linked List, Tree(Red-Black Tree) )를 활용해 추가 메모리를 사용하여 다음 데이터의 주소를 저장하는 것이다.
다음은 Linked list를 사용한 것이다. 인덱스가 충돌이 날 때, 인덱스가 가리키고 있는 linked list에 노드를 추가하여 값을 삽입한다.
데이터를 탐색할 때는 키에 대한 인덱스가 가리키고 있는 Linked list를 선형 검색하여, 해당 키에 대한 데이터를 반환한다.
삭제하는 것도 비슷하게, 키에 대한 인덱스가 가리키고 있는 Linked list에서, 그 노드를 삭제한다.
Separate changing 방식은 Linked List 구조를 사용하고 있기 때문에, 추가할 수 있는 데이타 수의 제약이 작다.
2) 개방 주소법(Open Addressing)
해시테이블 전체를 열린 공간으로 가정하고 충돌된 키를 일정한 방식에 따라서 찾아낸 빈공간에 저장
-대표적인 개방주소방식
- 선형조사(Linear Probing) : 현재 버킷 index로부터 고정폭 만큼씩 이동하여 순차적으로 검색해 비어 있는 버킷에 데이터를 저장한다.
- 이차조사(Quadratic Probing) : 해시의 저장순서 폭을 제곱으로 저장하는 방식이다. 예를 들어 처음 충돌이 발생한 경우에는 1만큼 이동하고 그 다음 계속 충돌이 발생하면 2^2, 3^2칸씩 옮기는 방식이다.
- 이중해싱(Double Hashing) : 2개의 해시함수를 사용해 해시된 값을 한번 더 해싱하여 규칙성을 없애버리는 방식이다. 해시된 값을 한번 더 해싱하여 새로운 주소를 할당하기 때문에 다른 방법들보다 많은 연산을 하게 된다.
해시 테이블의 성능
-키 값이 배열의 인덱스로 변환되기 때문에 탐색,저장,삭제가 빠르다. 평균 시간 복잡도가 O(1)이다.
-평균 시작 복잡도인 이유는 collision 때문이다.
| 평균적인 경우 | 최악의 경우 | |
| 탐색 | O(1) | O(N) |
| 삽입 | O(1) | O(N) |
| 삭제 | O(1) | O(N) |
관련 포스팅
2021.06.30 - [Algorithm/자료구조] - [Java] Hash Map / Hash Table / Tree Map
[Java] Hash Map / Hash Table / Tree Map
HashMap 클래스 HashMap 클래스는 Map 컬렉션 클래스에서 가장 많이 사용되는 클래스 중 하나이다. JDK 1.2부터 제공된 HashMap 클래스는 해시 알고리즘(hash algorithm)을 사용하여 검색 속도가 매우 빠르다.
hohodu.tistory.com
참고 및 출처
https://mangkyu.tistory.com/102
[자료구조] 해시테이블(HashTable)이란?
1. 해시테이블(HashTable)이란? [ HashTable(해시테이블)이란? ] 해시 테이블은 (Key, Value)로 데이터를 저장하는 자료구조 중 하나로 빠르게 데이터를 검색할 수 있는 자료구조이다. 해시 테이블이 빠른
mangkyu.tistory.com
Hash, Hashing, Hash Table(해시, 해싱 해시테이블) 자료구조의 이해
0_HJVxQPQ-eW0Exx7M.jpeg DATA들이 사용하기 쉽게 정리되어 있다. 자료구조는 도대체 무엇일까? 자료구조(Data-Structure)는 데이터들의 모임, 관계, 함수, 명령 등의 집합을 의미한다. 더 쉽게 표현하자면, 1)
velog.io
'Algorithm > 자료구조' 카테고리의 다른 글
| [자료구조] Union Find (0) | 2021.03.25 |
|---|---|
| [자료구조] 탐색(search) (0) | 2021.03.02 |
| [자료구조] DFS와 BFS (0) | 2021.02.24 |
| [자료구조] 그래프 (0) | 2021.02.24 |
| [자료구조] 동적 계획 (DP : Dynamic Programming) (0) | 2021.02.12 |