
들어가기전에
object proposal
end to end 학습
Abstract.
단일의 deep neural network로 object detection을 구현했습니다. SSD라고 불리는 접근법은 다양한 크기와 비율을 가진 default box들로 각 feature map에서 bounding box를 뽑아냅니다. predict를 할 때는 네트워크가 각 default box가 각각의 사물 카테고리에 속하는 score와 사물 모양에 잘 맞는 box를 만들어 냅니다. 게다가, 다양한 크기를 가지는 사물을 매끄럽게 변환한 다양한 feature map들을 결합하여 predict에 사용합니다. 쉽게 보면 object proposal들을 사용하는 방법들과 다릅니다. 그 이유는 proposal을 생성하는 부분과 pixel 또는 feature를 리샘플링하는 부분이 제거했으며 모든 계산을 단일 네트워크에서 진행합니다. 단일 네트워크로 학습을 쉽게 할 수 있고 detection에 필요한 요소를 통합했습니다.
결과로는 VOC2007에서 74.3%의 정확도(mAP)와 59fps가 나왔다고 합니다.
비교하자면 최신 Faster R-CNN모델보다 뛰어난 성능입니다.
1. Introduction
현재 최신 object detection 시스템에서 bounding box가설하기, pixel 또는 feature resample하기, 높은 퀄리티의 classifier 적용시키는 다양한 접근법이 있습니다.
당시에 SOTA는 Faster R-CNN이었습니다. 정확도도 높고 deep 한 network입니다. 하지만 계산량이 너무 많으며 좋은 하드웨어를 사용해도 실시간으로는 사용하기 어렵다. 제일 빨라봤자 7 fps 밖에 나오지 않는다. 따라서 속도를 올리려고 노력했지만 속도가 올라간 만큼 저확도가 감소하였습니다.
본 논문은 object proposal를 사용하지 않고 object detection을 할 수 있으며 VOC2007 test를 기준으로 Faster R-CNN의 경우 7 fps, 73.2%이며 YOLO의 경우 45 fps, 63.4%이다. 본 논문에서 소개하는 SSD의 경우 59 fps, 74.3%의 결과를 가져왔다고 합니다. 즉, 속도와 정확도 두 마리의 토끼를 동시에 잡았습니다.
우선 proposal생성과 resampling 단계를 제거하여 속도를 증가시켰습니다. 또한 정확도를 위해 다른 scale과 aspect ratio를 가지는 default box를 사용하였습니다. ( Faster-RCNN의 Anchor와 유사) 그 후에 다른 크기들의 feature map을 prediction에 사용하였습니다.
- YOLO 보다 빠르고 Faster-RCNN 보다 정확한 SSD를 소개합니다.
- SSD의 핵심은 작은 conv filter들을 사용한 default box들을 여러 feature map에 적용시켜 score와 box 좌표를 예측합니다.
- detection 정확도를 높이기 위해서 여러 크기의 다른 feature map들로부터 여러 크기의 predict를 수행하고 비율 또한 다르게 적용했습니다.
- end-to-end 학습을 할 수 있게 구축했으며 저해상도 이미지에서도 높은 정확도를 가집니다
- 여러 대회(PASCAL VOC, COCO, ILSVRC)에서 실험을 진행한 것을 소개합니다.
2. The Single Shot Detector(SSD)
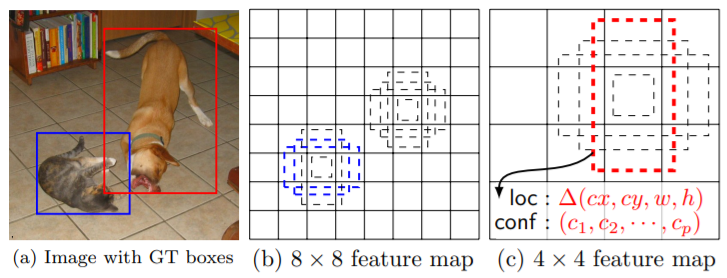
위 그림은 SSD Framework로
(a)훈련하는 동안 각 object에 대한 input image와 ground truth box만 필요로 합니다.
convolutional 방식에서 다른 크기의(4x4 그리고 8x8) feature map의 각 위치에 다른 비율의 default box set으로 평가한다. 각 default box에서 shape offset과 모든 object 카테고리에대한 confidence를 예측한다.
학습 시 default box와 ground truth box를 먼저 매칭한다.
2.1 Model
SSD는 NMS(non maximum suppression)를 거쳐 최종적으로 나오는 bbox와 score를 포함한 box들을 생각하는 feed-forward convolutional network(FFCNN)를 기반합니다. 밑의 그림은 단순한 FFCNN입니다.
Muiti-scale feature maps for detection
base network에서 끝이 생략된 conv feature layer를 추가했습니다. 이 layer들은 점진적으로 크기가 줄어들고 다양한 크기에서 prediction 하도록 했습니다. detection을 위한 convolutional model은 Overfeat 그리고 YOLO 같이 단일 크기의 feature map을 만드는 다른 feature layer입니다.
Convolutional predictors for detection
각각 더해진 feature layer은 prediction을 위해 conv filter가 사용된 세트를 만듭니다. 즉, 밑의 사진에서 SSD 네트워크 구조의 윗단을 가리킵니다.
m x n x p의 feature layer을 얻기 위해 각 conv layer로 부터 3 x 3 x p의 conv layer을 추가로 통과시킵니다. 즉, m x n 의 위치에 3 x 3 x p 의 kernel을 적용시킵니다. 이것을 detection에 사용합니다. bounding box는 default box의 위치로 알 수 있습니다.
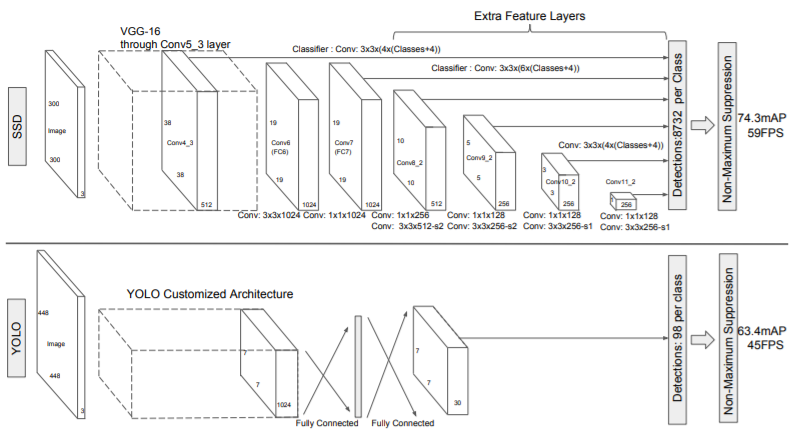
위의 사진은 SSD와 YOLO모델의 비교로 SSD모델은 base network의 끝에 다른 크기와 비율의 box offset을 예측하는 몇개의 feature layer를 추가한다.
2.2 Training
Maching strategy
학습을 하는 동안, default box는 gt box와 대응하여 network가 학습된다. 따라서, default box들의 위치, 크기 그리고 비율은 다양하게 선택되어야 한다. MultiBox의 최고 jaccard overlap과 함께 gt box와 default box를 매칭 시켰다. MultiBox와는 다르게 threshold인 0.5보다 크게 잡았다. 이렇게 하면 좀 더 정확하게 겹쳐야 default box가 선택이 된다. 즉, 학습을 좀 더 단순화시킨다.
Training objective
SSD 학습은 MultiBox에서 파생되었지만, 더 많은 object 목록을 가진다.
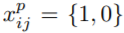
가 있다고 하자. 여기서 i는 default box의 index, j는 ground truth box의 index, 그리고 p는 object의 index이다. 위의 Matching Strategy을 적용시키면
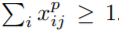
를 예측할 수 있다.
결국에는 전체 손실 함수는 localization loss(loc)와 confidence loss(conf)의 합으로 나타난다.
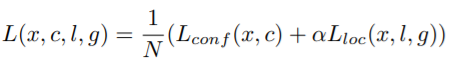
- N : ground truth box와 매칭된 default box의 개수(N이 0이면 loss 또한 0이다.)
- ㅣ : 예측한 box
- g : ground truth box
- c : confidence score(object일 확률)
- loc는 l과 g을 파라미터로 가지는 Smooth L1 loss function이다.
- α : weight term이며, cross validataion에서 1로 설정된다.
Choosing scales and aspect ratios for default boxs
다른 크기와 비율의 object를 인식하는 방법에는 여러 가지가 있다.
본 논문에서는 여러 가지의 크기와 비율을 가진 default box들을 이용한다. 다른 차원의 feature map들을 사용한 네트워크는 성능이 좋다. SSD 또한 다른 차원의 feature map을 사용한다. 위의 Convolutional predictors for detection의 그림에서와 같이 다른 차읜의 feature map에서 default box를 가져와 인식에 사용한다.
Hard negative mining
matching 단계가 지난 후에는 대부분의 default box들은 negative 일 것입니다. 이것은 positive와 negative 학습 데이터의 언밸런스 문제로 이어집니다. 따라서 모든 negative 데이터를 사용하는 것이 아니라 negative : positive = 3:1 로 사용합니다. 본 논문을 제작한 분들이 이 비율이 제일 optimal 하다고 합니다.
Data augmentation
input으로 사용할 object는 다양한 크기와 모양이 필요하다. 따라서 학습 이미지는 다음 3가지중에 하나를 sample한다.
- 전체적인 original input 이미지를 사용한다.
- 0.1, 0.3, 0.5, 0.7 또는 0.9의 jaccard overlap을 사용한다.
- 무작위로 sample들을 사용한다.
3. Experimantal Results
base network로는 VGG16을 적용시켰다고 한다. 하지만 완벽하게 그대로 사용한 것이 아니라 layer를 조금 변형시켜 적용했다고 한다.
3.1 PASCAL VOC2007
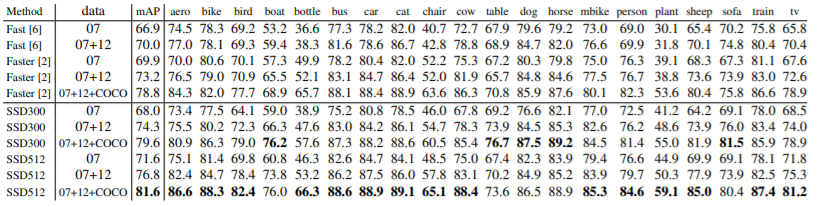
PASCAL VOC2007 데이터를 사용한 결과로 Fast R-CNN보다 SSC가 성능이 더 좋으며
더 큰 input 이미지는 더 나은 결과를 가져온다. ( 작은 object는 적은 정보를 가지고 있기 때문에 큰 object가 좋은데 Input 이미지 사이즈를 증가시키는 것은 작은 object를 감지를 향상시켜준다.)
3.2 Model analysis

- Data augmentation이 중요하다->data augmentation을 적용시켰을 때 8.8%의 성능이 향상되었다.
- 많은 default box 모양이 더 좋다->box를 예측하는 일이 더 쉬워진다.
- Atrous 는 더 빠르다->subsample된 atrous는 속도를 더 빠르게 한다.
- 여러 feature map을 사용하는 것이 성능을 향상시킨다.->아래 표에서 6개의 feature map을 사용하는 것이 아닌 마지막 feature map을 사용하지 않고 5개의 feature map을 사용하는 것이 더 좋은 성능이 나온다.

4.Conclusion
SSD는 multiple categories 1-stage detector이다. 제일 큰 특징은 여러 개의 featuremap으로부터 다양한 크기의 bounding box를 가져오는 것이다. 이것이 매우 효과적으로 성능 향상에 도움이 되었다. 다른 obejcet detector(faster R-CNN, YOLO 등)와 비교하여 높은 인식률과 속도를 보여줍니다. 마지막으로 R-CNN이나 영상에서 object tracking에서도 잘 사용될 것이다.
느낀점:
SSD는 object proposal 단계를 제거하고 여러개의 feature map으로부터 다양한 크기의 bounding box를 가져옴으로써 성능향상의 도움이 되어 Faster R-CNN보다 속도가 빠르고 정확한 detection이 된다는 것이 인상깊었다.
'Programmer > Deep Learning' 카테고리의 다른 글
| [논문리뷰] Rapid Object Detection using a Boosted Cascade of Simple Features (0) | 2020.04.21 |
|---|---|
| [논문리뷰] An Overview Of Face Liveness Detection 2 (0) | 2020.04.19 |
| [논문리뷰] An Overview of Face Liveness Detection1 (0) | 2020.04.18 |
| Precision(정밀도) , Recall(재현율) , Accuracy(정확도) , FLOPS (0) | 2020.04.08 |
| [논문리뷰] YOLACT ( Real-time Instance Segmentation ) (0) | 2020.03.28 |
들어가기전에
object proposal
end to end 학습
Abstract.
단일의 deep neural network로 object detection을 구현했습니다. SSD라고 불리는 접근법은 다양한 크기와 비율을 가진 default box들로 각 feature map에서 bounding box를 뽑아냅니다. predict를 할 때는 네트워크가 각 default box가 각각의 사물 카테고리에 속하는 score와 사물 모양에 잘 맞는 box를 만들어 냅니다. 게다가, 다양한 크기를 가지는 사물을 매끄럽게 변환한 다양한 feature map들을 결합하여 predict에 사용합니다. 쉽게 보면 object proposal들을 사용하는 방법들과 다릅니다. 그 이유는 proposal을 생성하는 부분과 pixel 또는 feature를 리샘플링하는 부분이 제거했으며 모든 계산을 단일 네트워크에서 진행합니다. 단일 네트워크로 학습을 쉽게 할 수 있고 detection에 필요한 요소를 통합했습니다.
결과로는 VOC2007에서 74.3%의 정확도(mAP)와 59fps가 나왔다고 합니다.
비교하자면 최신 Faster R-CNN모델보다 뛰어난 성능입니다.
1. Introduction
현재 최신 object detection 시스템에서 bounding box가설하기, pixel 또는 feature resample하기, 높은 퀄리티의 classifier 적용시키는 다양한 접근법이 있습니다.
당시에 SOTA는 Faster R-CNN이었습니다. 정확도도 높고 deep 한 network입니다. 하지만 계산량이 너무 많으며 좋은 하드웨어를 사용해도 실시간으로는 사용하기 어렵다. 제일 빨라봤자 7 fps 밖에 나오지 않는다. 따라서 속도를 올리려고 노력했지만 속도가 올라간 만큼 저확도가 감소하였습니다.
본 논문은 object proposal를 사용하지 않고 object detection을 할 수 있으며 VOC2007 test를 기준으로 Faster R-CNN의 경우 7 fps, 73.2%이며 YOLO의 경우 45 fps, 63.4%이다. 본 논문에서 소개하는 SSD의 경우 59 fps, 74.3%의 결과를 가져왔다고 합니다. 즉, 속도와 정확도 두 마리의 토끼를 동시에 잡았습니다.
우선 proposal생성과 resampling 단계를 제거하여 속도를 증가시켰습니다. 또한 정확도를 위해 다른 scale과 aspect ratio를 가지는 default box를 사용하였습니다. ( Faster-RCNN의 Anchor와 유사) 그 후에 다른 크기들의 feature map을 prediction에 사용하였습니다.
- YOLO 보다 빠르고 Faster-RCNN 보다 정확한 SSD를 소개합니다.
- SSD의 핵심은 작은 conv filter들을 사용한 default box들을 여러 feature map에 적용시켜 score와 box 좌표를 예측합니다.
- detection 정확도를 높이기 위해서 여러 크기의 다른 feature map들로부터 여러 크기의 predict를 수행하고 비율 또한 다르게 적용했습니다.
- end-to-end 학습을 할 수 있게 구축했으며 저해상도 이미지에서도 높은 정확도를 가집니다
- 여러 대회(PASCAL VOC, COCO, ILSVRC)에서 실험을 진행한 것을 소개합니다.
2. The Single Shot Detector(SSD)
위 그림은 SSD Framework로
(a)훈련하는 동안 각 object에 대한 input image와 ground truth box만 필요로 합니다.
convolutional 방식에서 다른 크기의(4x4 그리고 8x8) feature map의 각 위치에 다른 비율의 default box set으로 평가한다. 각 default box에서 shape offset과 모든 object 카테고리에대한 confidence를 예측한다.
학습 시 default box와 ground truth box를 먼저 매칭한다.
2.1 Model
SSD는 NMS(non maximum suppression)를 거쳐 최종적으로 나오는 bbox와 score를 포함한 box들을 생각하는 feed-forward convolutional network(FFCNN)를 기반합니다. 밑의 그림은 단순한 FFCNN입니다.
Muiti-scale feature maps for detection
base network에서 끝이 생략된 conv feature layer를 추가했습니다. 이 layer들은 점진적으로 크기가 줄어들고 다양한 크기에서 prediction 하도록 했습니다. detection을 위한 convolutional model은 Overfeat 그리고 YOLO 같이 단일 크기의 feature map을 만드는 다른 feature layer입니다.
Convolutional predictors for detection
각각 더해진 feature layer은 prediction을 위해 conv filter가 사용된 세트를 만듭니다. 즉, 밑의 사진에서 SSD 네트워크 구조의 윗단을 가리킵니다.
m x n x p의 feature layer을 얻기 위해 각 conv layer로 부터 3 x 3 x p의 conv layer을 추가로 통과시킵니다. 즉, m x n 의 위치에 3 x 3 x p 의 kernel을 적용시킵니다. 이것을 detection에 사용합니다. bounding box는 default box의 위치로 알 수 있습니다.
위의 사진은 SSD와 YOLO모델의 비교로 SSD모델은 base network의 끝에 다른 크기와 비율의 box offset을 예측하는 몇개의 feature layer를 추가한다.
2.2 Training
Maching strategy
학습을 하는 동안, default box는 gt box와 대응하여 network가 학습된다. 따라서, default box들의 위치, 크기 그리고 비율은 다양하게 선택되어야 한다. MultiBox의 최고 jaccard overlap과 함께 gt box와 default box를 매칭 시켰다. MultiBox와는 다르게 threshold인 0.5보다 크게 잡았다. 이렇게 하면 좀 더 정확하게 겹쳐야 default box가 선택이 된다. 즉, 학습을 좀 더 단순화시킨다.
Training objective
SSD 학습은 MultiBox에서 파생되었지만, 더 많은 object 목록을 가진다.
가 있다고 하자. 여기서 i는 default box의 index, j는 ground truth box의 index, 그리고 p는 object의 index이다. 위의 Matching Strategy을 적용시키면
를 예측할 수 있다.
결국에는 전체 손실 함수는 localization loss(loc)와 confidence loss(conf)의 합으로 나타난다.
- N : ground truth box와 매칭된 default box의 개수(N이 0이면 loss 또한 0이다.)
- ㅣ : 예측한 box
- g : ground truth box
- c : confidence score(object일 확률)
- loc는 l과 g을 파라미터로 가지는 Smooth L1 loss function이다.
- α : weight term이며, cross validataion에서 1로 설정된다.
Choosing scales and aspect ratios for default boxs
다른 크기와 비율의 object를 인식하는 방법에는 여러 가지가 있다.
본 논문에서는 여러 가지의 크기와 비율을 가진 default box들을 이용한다. 다른 차원의 feature map들을 사용한 네트워크는 성능이 좋다. SSD 또한 다른 차원의 feature map을 사용한다. 위의 Convolutional predictors for detection의 그림에서와 같이 다른 차읜의 feature map에서 default box를 가져와 인식에 사용한다.
Hard negative mining
matching 단계가 지난 후에는 대부분의 default box들은 negative 일 것입니다. 이것은 positive와 negative 학습 데이터의 언밸런스 문제로 이어집니다. 따라서 모든 negative 데이터를 사용하는 것이 아니라 negative : positive = 3:1 로 사용합니다. 본 논문을 제작한 분들이 이 비율이 제일 optimal 하다고 합니다.
Data augmentation
input으로 사용할 object는 다양한 크기와 모양이 필요하다. 따라서 학습 이미지는 다음 3가지중에 하나를 sample한다.
- 전체적인 original input 이미지를 사용한다.
- 0.1, 0.3, 0.5, 0.7 또는 0.9의 jaccard overlap을 사용한다.
- 무작위로 sample들을 사용한다.
3. Experimantal Results
base network로는 VGG16을 적용시켰다고 한다. 하지만 완벽하게 그대로 사용한 것이 아니라 layer를 조금 변형시켜 적용했다고 한다.
3.1 PASCAL VOC2007
PASCAL VOC2007 데이터를 사용한 결과로 Fast R-CNN보다 SSC가 성능이 더 좋으며
더 큰 input 이미지는 더 나은 결과를 가져온다. ( 작은 object는 적은 정보를 가지고 있기 때문에 큰 object가 좋은데 Input 이미지 사이즈를 증가시키는 것은 작은 object를 감지를 향상시켜준다.)
3.2 Model analysis
- Data augmentation이 중요하다->data augmentation을 적용시켰을 때 8.8%의 성능이 향상되었다.
- 많은 default box 모양이 더 좋다->box를 예측하는 일이 더 쉬워진다.
- Atrous 는 더 빠르다->subsample된 atrous는 속도를 더 빠르게 한다.
- 여러 feature map을 사용하는 것이 성능을 향상시킨다.->아래 표에서 6개의 feature map을 사용하는 것이 아닌 마지막 feature map을 사용하지 않고 5개의 feature map을 사용하는 것이 더 좋은 성능이 나온다.
4.Conclusion
SSD는 multiple categories 1-stage detector이다. 제일 큰 특징은 여러 개의 featuremap으로부터 다양한 크기의 bounding box를 가져오는 것이다. 이것이 매우 효과적으로 성능 향상에 도움이 되었다. 다른 obejcet detector(faster R-CNN, YOLO 등)와 비교하여 높은 인식률과 속도를 보여줍니다. 마지막으로 R-CNN이나 영상에서 object tracking에서도 잘 사용될 것이다.
느낀점:
SSD는 object proposal 단계를 제거하고 여러개의 feature map으로부터 다양한 크기의 bounding box를 가져옴으로써 성능향상의 도움이 되어 Faster R-CNN보다 속도가 빠르고 정확한 detection이 된다는 것이 인상깊었다.
'Programmer > Deep Learning' 카테고리의 다른 글
| [논문리뷰] Rapid Object Detection using a Boosted Cascade of Simple Features (0) | 2020.04.21 |
|---|---|
| [논문리뷰] An Overview Of Face Liveness Detection 2 (0) | 2020.04.19 |
| [논문리뷰] An Overview of Face Liveness Detection1 (0) | 2020.04.18 |
| Precision(정밀도) , Recall(재현율) , Accuracy(정확도) , FLOPS (0) | 2020.04.08 |
| [논문리뷰] YOLACT ( Real-time Instance Segmentation ) (0) | 2020.03.28 |