
소개
YOLO는 You Only Look Once의 약자이다.
대략 R-CNN은 너무 느렸으며(5초), Fast R-CNN도 0.5프레임으로 느렸고, Faster R-CNN도 7프레임이 최대였다.
이때 YOLO가 등장하여 45프레임을 보여주었고 빠른 버전의 경우 155프레임을 기록하며 사람들을 놀라게 했다.
R-CNN - Fast R-CNN - Faster R-CNN - YOLO는 대략 10배씩 속도차이가 난다.
게다가 성능도 FasterR-CNN에 비해 크게 떨어지지 않았다.
기존 방법과의 차이점
R-CNN 계열의 검출 네트워크들은 영상에서 오브젝트가 있을 것 같은 후보(ROI - Region If Interest : 관심영역)를 먼저 뽑는다. 후보로 뽑힌 ROI(영상의 작은 부분) 들은 분류기(Classification network)에 의해 클래스 분류가 이뤄지고 경계박스(Bound Box)를 찾는다.
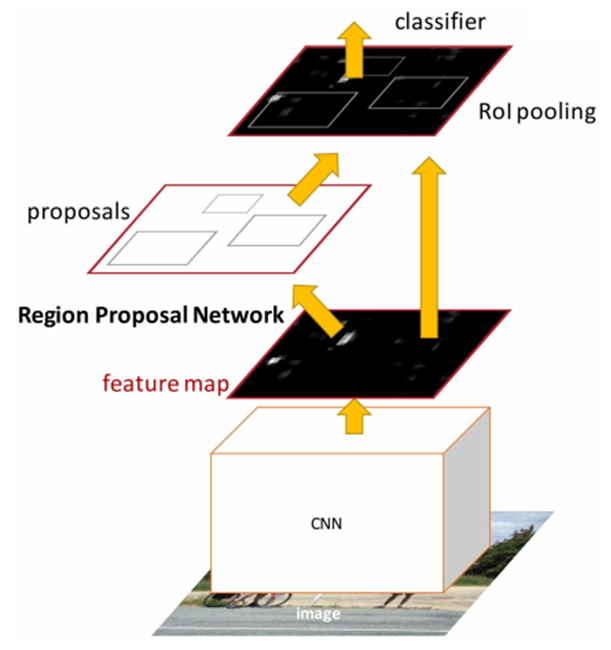
Region Proposal Network가 영상에서 오브젝트가 있을 것 같은 영역(Region)들을 뽑아서 (여기에 어떤 클래스가 있는지 확인해보라고) 제안(proposal)한다.
제안되 영역이 어떤 클래스인지 분류하기 위해서 classifier의 많은 레이어들을 통과해야만 한다.
즉 아래쪽에 하얀 박스로 표시된 CNN을 통해 경계 박스를 얻고 그 경계박스안에 어떤 클래스가 있는지 classifier(분류 네트워크-역시 NN)로 검사를 한다.
각각 역할이 다른 3개의 네트워크가 하나로 연결되어 있어 전체를 한번에 학습시킬 수 있으므로 결국 하나라고 말할 수도 있다.(End to End)
앞단의 CNN이 특징추출기의 역할을 하며, RPN(Region Proposal Network)는 오브젝트가 있을 법한 경계 박스를 추천하며, classifier는 앞의 두 네트워크가 전달하는 특징 데이터와 경계 박스 위치를 받아서 분류한다.
하지만 여전히 느리다.
기존의 R-CNN등이 느린 이유는 Proposal 수도 많고, 그 과정에서의 오버헤드도 크기 때문이다.
영상에서 오브젝트의 경계박스를 찾는 방법은 크게 2가지가 있다.
Proposal방식과 grid방식이다.
YOLO는 실시간성을 확보하기 위해 Proposal의 수가 적은 grid 방식을 더욱 발전시켜서 사용했다.
YOLO 네트워크
YOLO는 네트워크의 최종 출력단에서 경계박스를 위치 찾기와 클래스 분류가 동시에 이뤄진다.
단 하나의 네트워크가 한번에 특징도 추출하고, 경계박스도 만들고, 클래스도 분류한다.
그러므로 간단하고 빠르다.

좌측의 입력 영상이 네트워크를 통과하면 중앙의 2개의 데이터를 얻는다.
이것이 네트워크의 최종 출력이다.
이 안에는 수많은 경계 박스들과 영상을 7X7그리드로 나눴을 때 해당 그리드 셀안에는 어떤 클래스가 있는지에 대한 정보(위 중앙 그림 2개)가 인코딩되어 있다.
우측의 이미지는 네트워크의 최종 출력물을 이용해 생성하는 것으로 네트워크가 직접 생성한 것이 아니다.
가운데 위쪽은 경계 박스에 대한 정보이다. 서오 다른 크기의 상당히 많은 경계 박스들이 그려져있다.
네트워크는 영상을 7X7그리드로 나눈다. 각 그리드에서 중심을 그리드 안쪽으로 하면서 크기가 일정하지 않은 경계박스를 2개씩 생성한다. 그리드 셀이 7*7=49 개이므로 경계 박스는 총 98개가 만들어진다.
이 중 경계 박스 안쪽에 어떤 오브젝트가 있을 것 같다고 확신(confidence score)할수록 박스를 굵게 그려준다.
굵은 경계 박스들만 남기고 얇은 경계 박스(어떤 오브젝트도 없는 것 같다고 생각되는 것들)을 지운다.
남은 후보 경계박스들을 NMS(Non-maximum suppression : 비최댓값 억제) 알고리즘을 이용해 선별하면 우측의 이미지처럼 3개만 남게 된다.
남은건 경계 박스의 색깔이다.
경계 박스의 색깔은 클래스를 의미한다.
중앙의 아래쪽에 이미지가 7X7의 그리드로 분할되어 총 49개의 그리드 셀이 만들어졌다.
각 그리드 셀은 해당 영역에서 제안한(proposal) 경계 박스안의 오브젝트가 어떤 클래스인지를 컬러로 표현하고 있다.
그러므로 최종적으로 남은 3개의 경계 박스 안에 어떠한 클래스가 있는지 알 수 있다.
그래서 우측의 최종 결과를 얻는다.
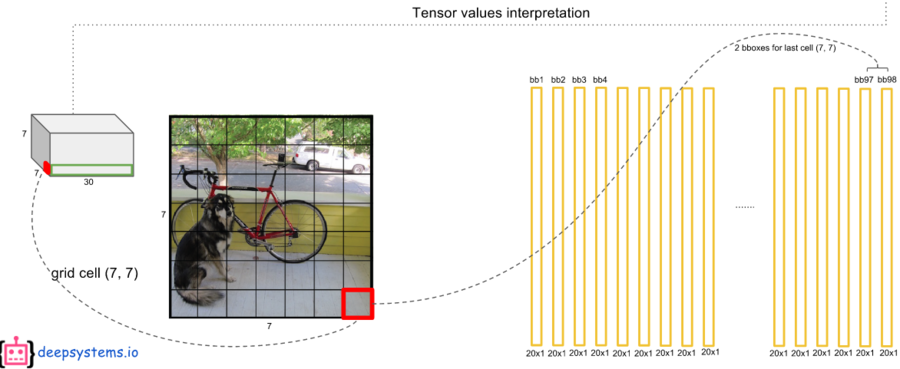
네트워크가 생성하는 경계 박스의 숫자는 그리드 셀의 2배이다.
그리드 셀이 49개이므로 경계박스는 총 98개가 만들어진다.
ROI 혹은 오브젝트 후보라고 할 수 있는 이 경계박스들은 threshold(0.5)보다 작으면 지워준다. (얅은 경계박스 지워주기)
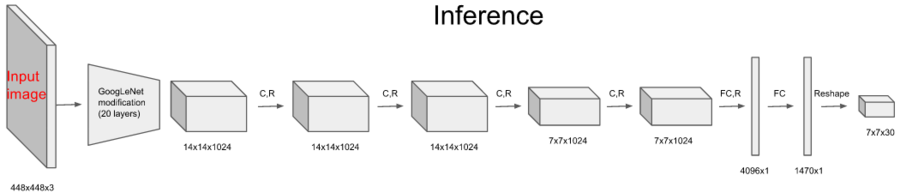
네트워크 구조는 직선적이다. GoogleLeNet을 약간 변형시켜서 특징 추출기로 사용했다.
이휴 컨볼루션 레이어(C.R) 4회, 풀 커넥션 레이어(FC.R) 2회 하고 사이즈를 7x7x30으로 조정하면 끝난다.
이 마지막 특징 데이터 7x7x30가 바로 예측 결과이며 이 안에 경계박스와 클래스 정보 등 모든 것이 들어있다.
무엇이 들어있는지 자세히 보자.

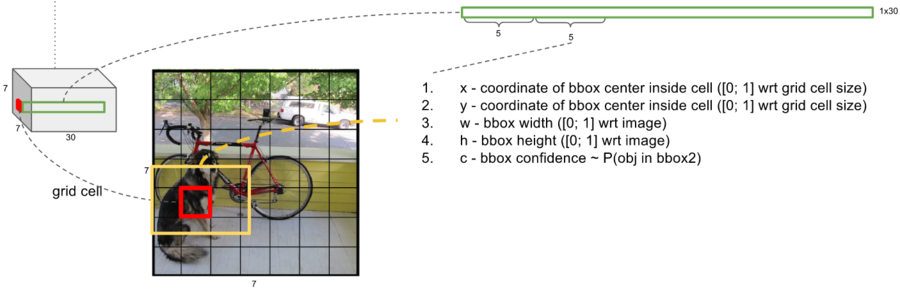
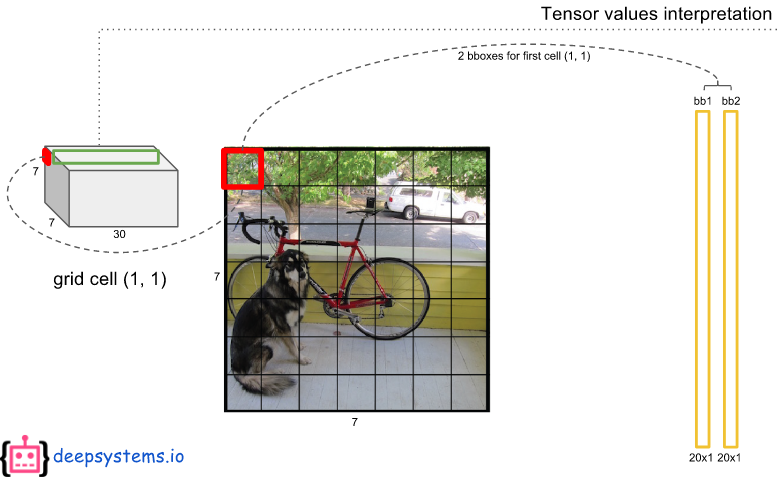
왼쪽 빨간점으로 표시한 부분을 7X7 그리드 셀 중에 하나로 이미지에서 개의 중앙 부분에 해당한다.
그리고 빨간색 박스보다 큰 노란색 박스가 바로 빨간색 그리드 셀에서 예측한 경계박스이다.
7x7은 영상을 7x7의 격자로 나눈것이다.
30개의 채널은 (경계 박스의 정보 4개(x,y,w,h) , 경계 박스안에 오브젝트가 있을 확률(confidence)) x2, 어떤 클래스일 확률 20개로 구성된다.
경계 박스 정보 x , y : 노란색 경계 박스의 중심이 빨간 격자 셀의 중심에서 어디에 있는가.
경계 박스 정보 w, h : 노란색 경계 박스의 가로 세로 길이가 전체 이미지 크기에 어느 정도 크기를 갖는가
만약 경계 박스가 위의 그림처럼 되었다면 x,y는 모두 0.5정도이고 w,h는 각각 2/7,4/7 정도가 될 것이다.
노란색 경계 박스는 반드시 그 중심이 빨간 그리드 셀 안에 있어야 하며, 가로와 세로 길이는 빨간 그리드 셀보다 작을 수도 있고 그림처럼 클 수도 있다. 또한 정사각형일 필요도 없다.
빨간 그리드 셀 내부 어딘가를 중심으로 하여 근처에 있는 어떤 오브젝트를 둘러싸는 직사각형의 노란색 경계 박스를 그리는 것이 목표이다.
노란색 경계박스가 바로 ROI, 오브젝트 후보이다.
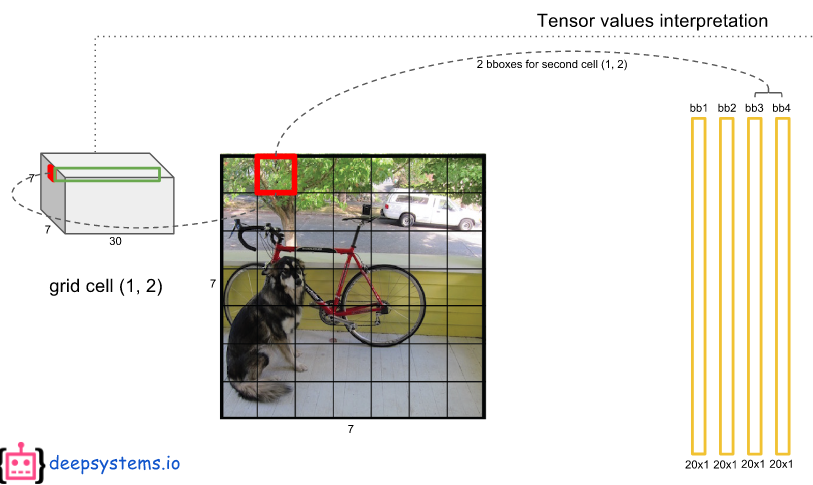
이것을 2개 만든다.
30개의 채널 중에서 앞에 5개는 1번째 경계 박스의 정보가 있으며 다음의 5개에는 2번째 경계 박스의 정보를 가지고 있다.
2번째 경계 박스는 1번째 것과 모양이 비슷할 수도 있고 다를 수도 있다.
위 그림에서는 1번째 경계박스와 다른 모양의 2번 경계박스를 예시로 보여주었다.

30개의 채널의 뒷부분(20)에는 해당 그리드 셀(빨간색 박스)에 오브젝트가 만약 있다면 그것이 어떤 클래스일지에 대한 확률이 저장되어 있다.
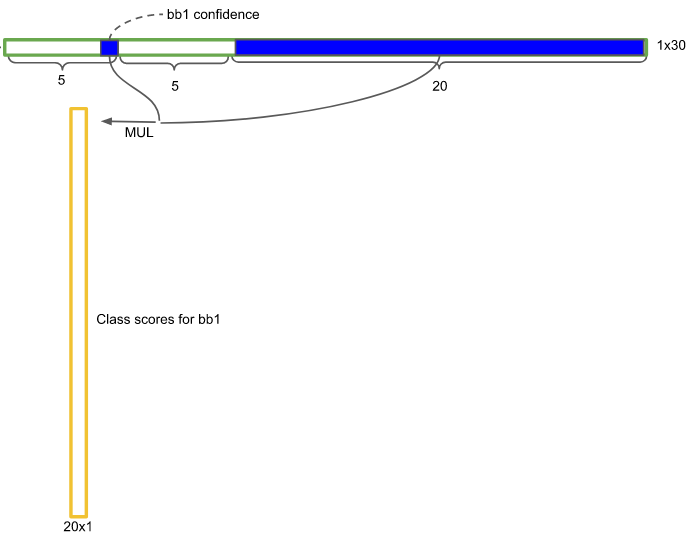
각 그리드 셀에는 셀의 주위 혹은 셀 안쪽에 어떤 오브젝트가 있을 거라고 예측한 2개의 경계박스가 있다.
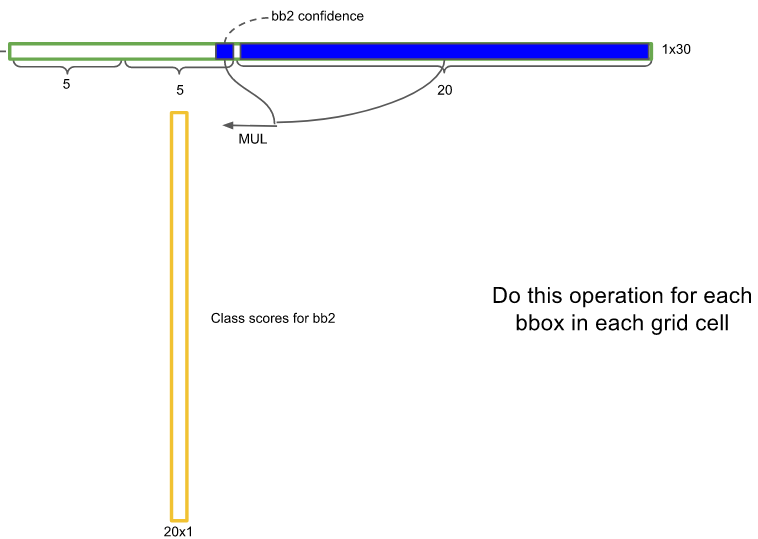
각 경계박스는 오브젝트가 있을 확률(confidence)을 가지고 있다.
이 스칼라 값(숫자 1개)을 그리드 셀의 클래스 분류 확률과 곱하면 경계박스의 클래스 분류 확률을 구할 수 있다.
이것이 위 그림의 긴 노란색 박스이다.
bb1(bound box 1) 즉 첫번째 후보의 경계박스에 대한 클래스 점수표이다.
경계박스의 오브젝트가 있을 확률(confidence)가 매우 낮다면 (0에 가깝다면) 그곳에 어떠한 클래스가 있는지에 대한 정보도 매우 낮아지게 된다.


클래스 첫번째 자리는Dog일 확률이다. dog일 확률을 높은 값부터 낮은 값으로 정렬한다.
여기까지 하면 해당 경계 박스의 클래스가 무엇인지 알 수 있다.
만약 위의 98개의 클래스 점수 표 중에서 97개가 0이고 하나만 0이 아니면 해당 오브젝트가 그 위치에 있다는 것을 간단하게 알 수 있다.
하지만 0이 아닌 노란 박스가 여러개 있을 수 있다.
특히 오브젝트의 크기가 큰 경우 더욱 그러하다.
이것들을 제거하기 위해서 NMS 알고리즘을 사용하여 중복이 되는 경계박스들을 제거하여 오직 하나의 경계 박스만 남긴다.
NMS는 여러 경계 박스들이 겹쳐 있을 때에는 그중에서 최대값을 갖는 하나의 오브젝트만 빼고 나머지를 지운다.(억제한다.)
그러나 여러 경계 박스들이 겹쳐있지 않을때에는 각 경계 박스들은 서로 다른 오브젝트의 경계 박스일 것이라고 생각하고 경계 박스들을 그냥 둔다.
테스트 결과 NMS을 사용하면 mAP 성능이 2-3%상승한다. NMS를 사용하지 않더라도 충분한 성능이 나오므로 NMS가 반드시 필요한 것은 아니라고 한다.


YOLO는 7x7개의 그리드 셀에서 각각 2개의 경계박스 후보를 예측한다.
그러므로 총 98개의 경계박스를 예측한다.
20개의 클래스 중에서 우선 dog만 살펴보자
우선 클래스의 신뢰도 점수가 0.2보다 작은 것은 모두 0으로 셋팅한다. ->첫번째 : threshold 사용
경계 박스의 신뢰도 점수가 어떤 클래스(예를 들어 개)에 대해서 신뢰 점수가 낮다면 그 경계박스 안에 뭐가 있는지는 아직 모르겠지만 최소한 그 클래스(개)는 아닐 것이라고 판단한다.
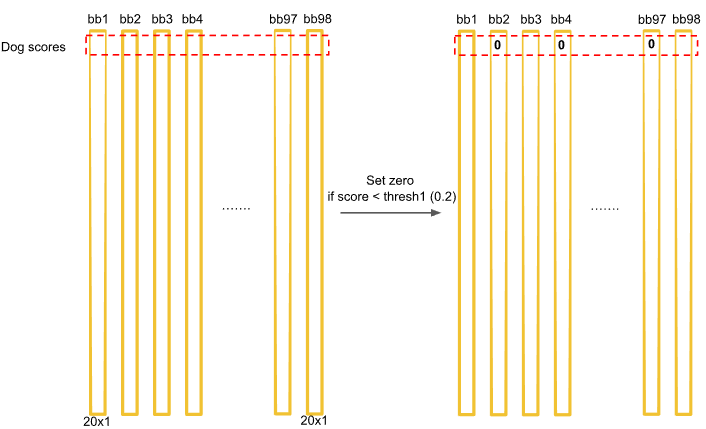

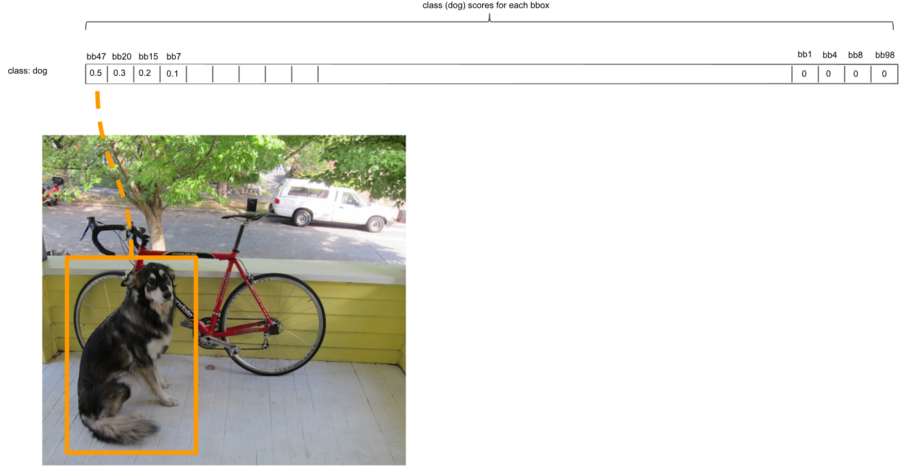
dog에 대한 두번째 : bbox confidence의 값을 큰것부터 작은것으로 내림차순 정렬하면 위와 같이 1X98크기의 배열을 얻게 된다.
위 그림에서 0.2보다 작은 것은 모두 지웠는데 0.1이 남아있다. 아마 오타이거나 혹은 0.1의 신뢰도가 어느 정도인지 그림으로 보여주기 위함같다. 신뢰도가 0.2보다 작은 것은 모두 지운 후에 개일 활률이 높은 경계박스가 3개 남았다.
개 후보 경계박스 3개를 살펴보자.
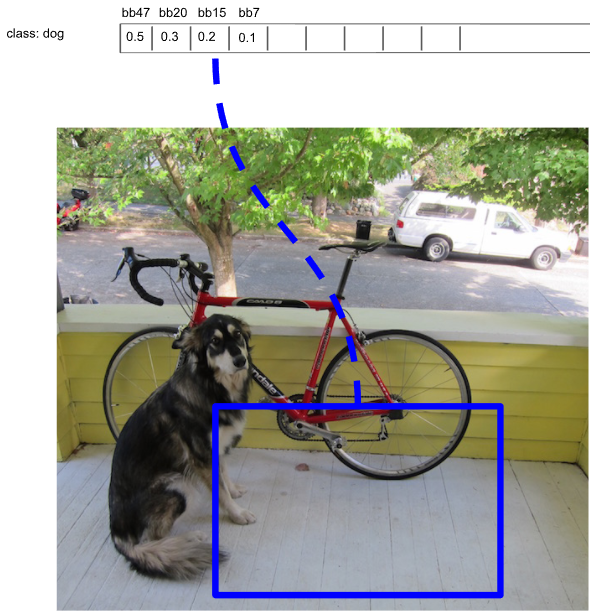
세번째 : 두개씩 경계 박스를 비교하여 IOU가 0.5가 넘으면(많이 겹치면) 경계 박스를 없애준다. (NMS)

초록색 경계박스도 개를 어느정도 잘 포착했다.
그러나 개의 다리와 엉덩이 부분은 포착하지 못했기 때문에 오렌지색 경계 박스보다는 나쁘다.
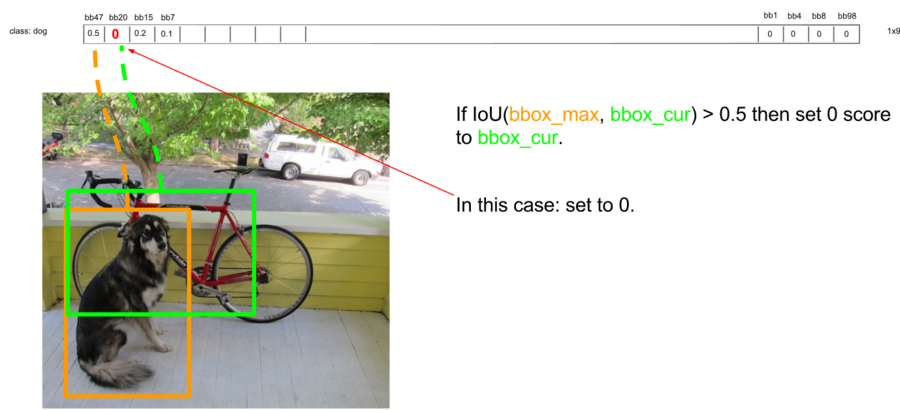
현재 경계박스 신뢰도가 가장 높은 첫번째 값 0.5가 bbox_max이다.
두번째로 높은 신뢰도를 갖는 초록색 경계박스의 값은 원래 0.3이었다.
그런데 두 경계박스의 겹치는 부분이 50%가 넘는다.
이런 경우 둘 중 하나는 중복일 것이라고 판다, 둘 중 신뢰도가 낮은 것을 지워준다.
그래서 0.3의 신뢰도 값을 0으로 설정한다.

개에 대해서 3번째로 높은 신뢰도를 갖는 파란 경계박스는 신뢰도가 가장 높은 오렌지색 경계 박스와 겹치는 부분이 50%가 넘지 않는다.
그렇다면 파란색 경계 박스 안에는 좌측의 개가 아닌 또 다른 개가 있을 수도 있다고 판단한다.
이런 경우는 신뢰도 값을 건드리지 않고 그냥 건너 뛴다.(continue)
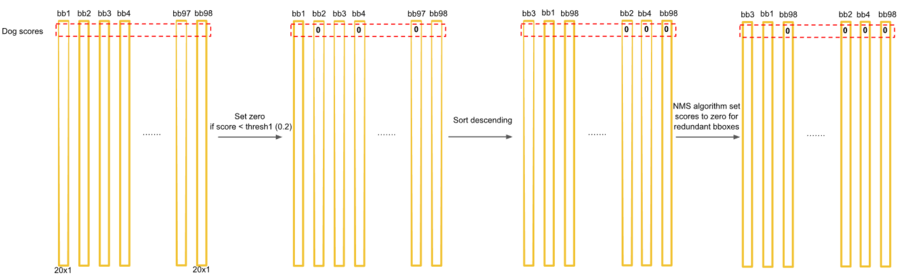
지금까지는 개에 대해서만 중복 경계 박스를 지웠다.
개에 대해 정렬한 1X20(첫번째 행)에서는 경계 박스2개(오렌지색과 파란색)만 남고 나머지 18개는 모두 0이 되었다.
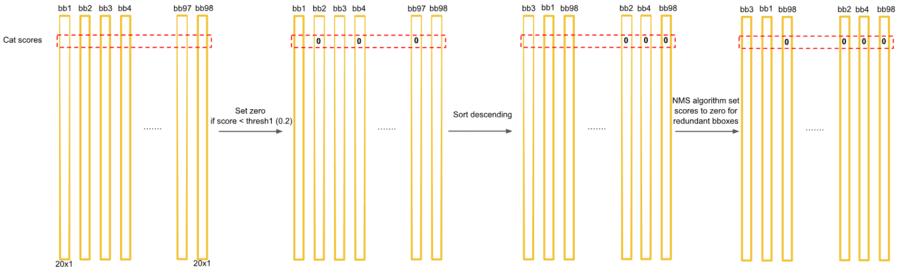
이제 남은 19개의 클래스(두번째 행부터 마지막 행까지)에 대해서도 같은 작업을 해준다.
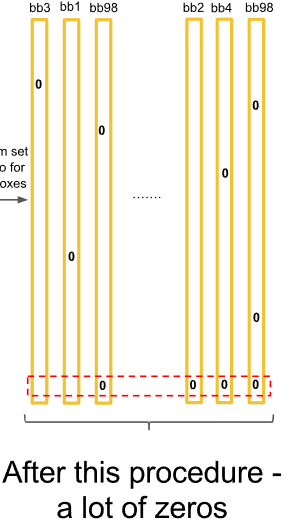
그러면 대부분의 값은 0이 될 것이다.
하지만 아직 한단계가 더 남았다.
사진에서는 개가 1마리 뿐밖에 없었는데 개에 대한 경계 박스가 오렌지색, 파란색 2개가 남아있다.
파란색 경계 박스에는 개가 없었다. 이것을 지워주어야 한다.
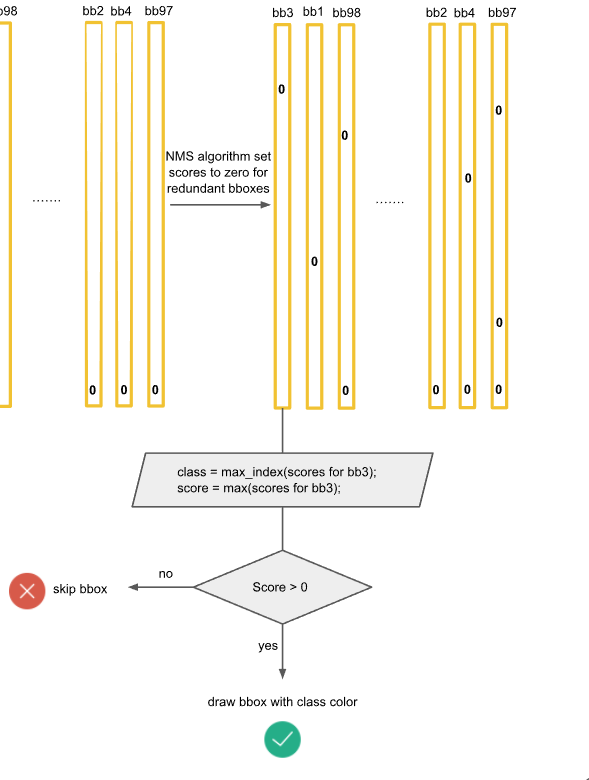
bb3은 20개 클래스에 대한 신뢰점수를 가지고 있다.
20개 신뢰점수 중 가장 큰 값을 가지는 클래스가 바로 경계 박스의 컬러이다. ->경계 박스의 클래스 컬러를 정해 그려준다.
만약 가장 큰 값이 0인 경우, 즉 해당 그리드 셀에서의 클래스 신뢰도가 전부 0이라면 bb3에는 오브젝트가 없는 것이다.
그러면 당연히 경계 박스를 그리지 않는다.(skip)
이런 과정을 거쳐서 각 그리도 셀에서는 최댓값을 갖는 클래스 하나와 또 다른 클래스 하나 총 2개가 나타날 수 있다.
만약 한 그리드 셀에서 2개의 클래스가 검출되었다면 오브젝트들이 겹쳐있을 확률이 높을 것이다.
하나의 그리드 셀에서 클래스가 같은 2개의 오브젝트는 나올 수 없는 구조이다.
위의 예에서 개일 확률이 있는 2개의 경계 박스 중에서 오렌지색만 진짜이고 파란색 경계 박스는 잘못된 것이었다.
파란색 경계 박스는 신뢰점수가 0.5이하이므로 나중에 지워진다.

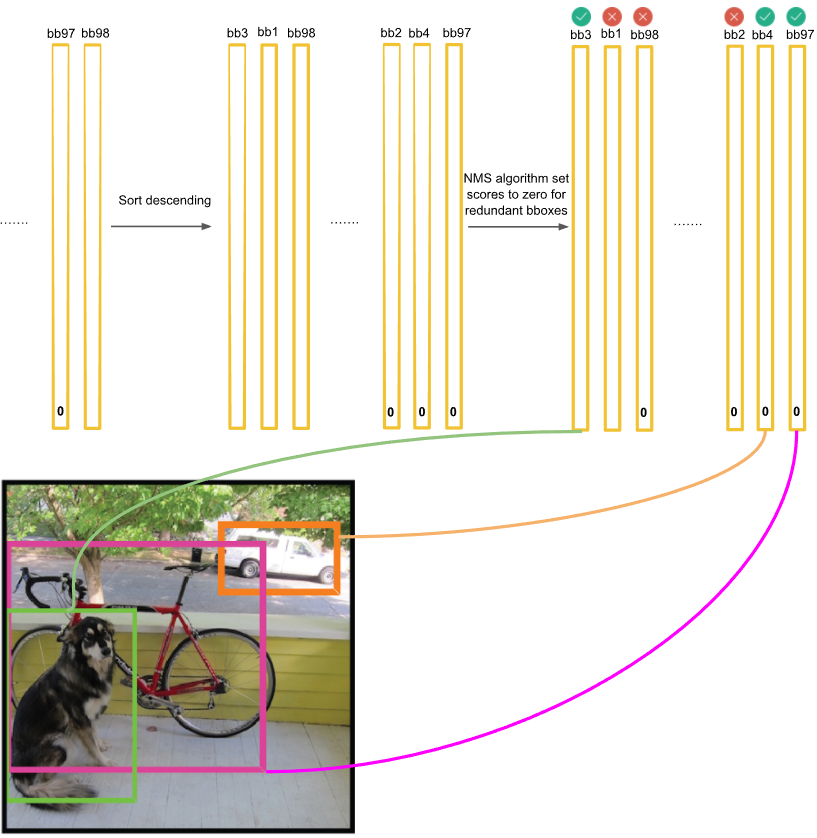
최종적으로 3개의 경계 박스만이 남았다. 경계 박스의 클래스는 컬러로 나타냈다.
학습
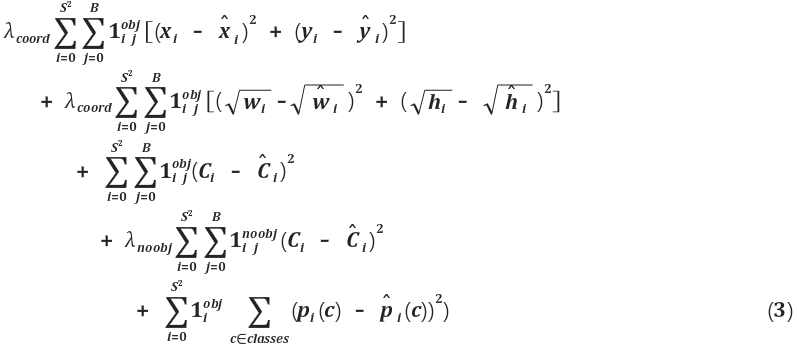
S는 격자(grid)의 수를 의미하고 B는 각 그리드 셀이 예측하는 경계 박스의 수이다.(S=7,B=2)
로스 함수를 보면 네트워크를 어떻게 학습시켰는지 파악할 수 있다.
sum-squared error를 사용한 이유는 단지 최적화하기 편해서일 뿐 이것이 평균 정밀도를 최대화하는데 최적의 함수는 아니다.
49개의 그리드셀의 대부분은 오브젝트가 없다. 극단적으로 49개 중에서 1개에만 오브젝트가 나타날 수도 있다.
이 현상으로 인해 각 그리드 셀은 오브젝트가 있을 것 같다는 신뢰점수를 만들어야 하는데, 대부분의 셀에 오브젝트가 없기 때문에 신뢰 점수가 0에 가까워진다.
이 문제를 해결하기 위해서 오브젝트가 있는 경우에 좌표 및 클래스 예측 로스는 키우고, 오브젝트가 없는 경우는 로스를 줄였다.
그것이
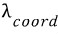
=5 ,
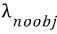
=0.5이다.
오브젝트가 있는 경우에만 학습을 제대로 하라고 로스를 5배 키우고 오브젝트가 없는 경우는 로스를 반으로 줄인다.
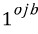
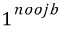
로 오브젝트가 있는 셀과 없는 셀을 구분한다.
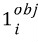
는 오브젝트가 있는 그리드셀 i이다. 경계 박스와는 관계 없다.
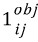
는 그리드셀 i에 있는 j번째 경계 박스가 예측한 것으로 예측에 대한 책임을 져야 한다.
이렇게 하면 오브젝트가 있는 그리드셀 i 에서만 로스가 발생하며 오브젝트가 없는 그리드셀들에서는 loss계산을 하지 않는다.
경계 박스 예측기들은 해당 셀에 오브젝츠가 있을 경우에만 잘 예측하면 된다.
총 5종류의 로스를 계산한다.
1th : 경계 박스의 x, y 좌표 학습하기
- 실제로 오브젝트가 i 에 있을 때 그리드셀i 에서 예측한 경계박스j 가 정답과 같도록 학습한다.
- 그리드셀이 예측하는 2개의 경계 박스(j=0, j=1) 모두 정답과 같아지도록 유도한다.
2th : 경계 박스의 width, height 학습하기
- 첫번째와 동일한데 단지 루트를 씌워서 사용한 것만 다르다.
큰 경계박스에서는 width, height 를 조금만 키워도 넓이가 확 증가한다. 미분값이 크다.
작은 경계 박스에서는 w,h 를 많이 키워도 넓이의 변화가 크지 않다. 미분값이 작다.
sum-squared error 를 사용하면 박스가 큰것과 작은것의 미분 차이가 크게 나기 때문에 이를 반영하기 위해 루트를 사용했다.
3th : 그리드 셀 i 에 오브젝트가 있을 경우 클래스 예측하기
- 가장 평범한 로스이다. 이 오브젝트가 뭔지 예측해라
4th : 그리드 셀 i 에 오브젝트가 없을 경우 클래스 예측하기
- 3th 에 비해 가중치가 0.5 이다. 그러므로 3th 이 2배 더 중요하다.
오브젝트가 없는 그리드셀에서는 클래스 분류 정확도가 좀 낮아도 괜찮다. 어차피 배경이니까, 배경일 확률만 다른것보다 좀 더 높으면 된다.
가중치가 낮으므로 오브젝트가 있는 셀(3th) 에서는 더 정확히 클래스 분류 하게 된다.
5th : 여기에는 B 에 대한 Sum 이 없다. 각 그리드셀 i 에서 경계박스는 2번(B=2) 예측하지만 클래스 확률 c(20종류) 는 공유하기 때문이다.
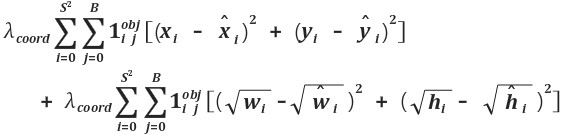
위의 2줄은 좌표(coordinate) 부분을 학습하기 위한 것이다.
S는 격자의 수를 의미하고 B는 각 그리드셀이 예측하는 경계박스의 수이다.
7X7=49개의 그리드 셀이 경계박스를 2개씩 예측하므로 2중 for문 형태이다.
해당 셀에 오브젝트가 있을 때만 로스를 구해서 최적화한다.
셀에 오브젝트가 없는 경우에는 좌표 예측이 무엇이든 상관 없다.
coordError = 0
for ( i = 0 ; i < S*S < i++){ // 7 * 7
for( j = 0 ; j < B < j++){ // 2
if(해당 셀에 진짜로 오브젝트가 있으면){
coordError += ... // 에러다. 학습을 통해 에러를 줄여 나간다.
}
else{
//해당 셀에 오브젝트가 없으면 신경쓰지 않는다.
}
}
}
[출처] YOLO, Object Detection Network |작성자 sogangori
'Programmer > Deep Learning' 카테고리의 다른 글
| [논문리뷰]DeepFace: Closing the Gap to Human-Level Performance in Face Verification (0) | 2020.07.02 |
|---|---|
| [논문리뷰] Deep Residual Learning for Image Recognition (0) | 2020.05.03 |
| [논문리뷰] Histograms of Oriented Gradients for Human Detection (0) | 2020.04.28 |
| YOLO 튜토리얼 3. Implementing the forward pass of the network (0) | 2020.04.26 |
| YOLO 튜토리얼 2. Creating the layers of the network architecture (0) | 2020.04.26 |
소개
YOLO는 You Only Look Once의 약자이다.
대략 R-CNN은 너무 느렸으며(5초), Fast R-CNN도 0.5프레임으로 느렸고, Faster R-CNN도 7프레임이 최대였다.
이때 YOLO가 등장하여 45프레임을 보여주었고 빠른 버전의 경우 155프레임을 기록하며 사람들을 놀라게 했다.
R-CNN - Fast R-CNN - Faster R-CNN - YOLO는 대략 10배씩 속도차이가 난다.
게다가 성능도 FasterR-CNN에 비해 크게 떨어지지 않았다.
기존 방법과의 차이점
R-CNN 계열의 검출 네트워크들은 영상에서 오브젝트가 있을 것 같은 후보(ROI - Region If Interest : 관심영역)를 먼저 뽑는다. 후보로 뽑힌 ROI(영상의 작은 부분) 들은 분류기(Classification network)에 의해 클래스 분류가 이뤄지고 경계박스(Bound Box)를 찾는다.
Region Proposal Network가 영상에서 오브젝트가 있을 것 같은 영역(Region)들을 뽑아서 (여기에 어떤 클래스가 있는지 확인해보라고) 제안(proposal)한다.
제안되 영역이 어떤 클래스인지 분류하기 위해서 classifier의 많은 레이어들을 통과해야만 한다.
즉 아래쪽에 하얀 박스로 표시된 CNN을 통해 경계 박스를 얻고 그 경계박스안에 어떤 클래스가 있는지 classifier(분류 네트워크-역시 NN)로 검사를 한다.
각각 역할이 다른 3개의 네트워크가 하나로 연결되어 있어 전체를 한번에 학습시킬 수 있으므로 결국 하나라고 말할 수도 있다.(End to End)
앞단의 CNN이 특징추출기의 역할을 하며, RPN(Region Proposal Network)는 오브젝트가 있을 법한 경계 박스를 추천하며, classifier는 앞의 두 네트워크가 전달하는 특징 데이터와 경계 박스 위치를 받아서 분류한다.
하지만 여전히 느리다.
기존의 R-CNN등이 느린 이유는 Proposal 수도 많고, 그 과정에서의 오버헤드도 크기 때문이다.
영상에서 오브젝트의 경계박스를 찾는 방법은 크게 2가지가 있다.
Proposal방식과 grid방식이다.
YOLO는 실시간성을 확보하기 위해 Proposal의 수가 적은 grid 방식을 더욱 발전시켜서 사용했다.
YOLO 네트워크
YOLO는 네트워크의 최종 출력단에서 경계박스를 위치 찾기와 클래스 분류가 동시에 이뤄진다.
단 하나의 네트워크가 한번에 특징도 추출하고, 경계박스도 만들고, 클래스도 분류한다.
그러므로 간단하고 빠르다.
좌측의 입력 영상이 네트워크를 통과하면 중앙의 2개의 데이터를 얻는다.
이것이 네트워크의 최종 출력이다.
이 안에는 수많은 경계 박스들과 영상을 7X7그리드로 나눴을 때 해당 그리드 셀안에는 어떤 클래스가 있는지에 대한 정보(위 중앙 그림 2개)가 인코딩되어 있다.
우측의 이미지는 네트워크의 최종 출력물을 이용해 생성하는 것으로 네트워크가 직접 생성한 것이 아니다.
가운데 위쪽은 경계 박스에 대한 정보이다. 서오 다른 크기의 상당히 많은 경계 박스들이 그려져있다.
네트워크는 영상을 7X7그리드로 나눈다. 각 그리드에서 중심을 그리드 안쪽으로 하면서 크기가 일정하지 않은 경계박스를 2개씩 생성한다. 그리드 셀이 7*7=49 개이므로 경계 박스는 총 98개가 만들어진다.
이 중 경계 박스 안쪽에 어떤 오브젝트가 있을 것 같다고 확신(confidence score)할수록 박스를 굵게 그려준다.
굵은 경계 박스들만 남기고 얇은 경계 박스(어떤 오브젝트도 없는 것 같다고 생각되는 것들)을 지운다.
남은 후보 경계박스들을 NMS(Non-maximum suppression : 비최댓값 억제) 알고리즘을 이용해 선별하면 우측의 이미지처럼 3개만 남게 된다.
남은건 경계 박스의 색깔이다.
경계 박스의 색깔은 클래스를 의미한다.
중앙의 아래쪽에 이미지가 7X7의 그리드로 분할되어 총 49개의 그리드 셀이 만들어졌다.
각 그리드 셀은 해당 영역에서 제안한(proposal) 경계 박스안의 오브젝트가 어떤 클래스인지를 컬러로 표현하고 있다.
그러므로 최종적으로 남은 3개의 경계 박스 안에 어떠한 클래스가 있는지 알 수 있다.
그래서 우측의 최종 결과를 얻는다.
네트워크가 생성하는 경계 박스의 숫자는 그리드 셀의 2배이다.
그리드 셀이 49개이므로 경계박스는 총 98개가 만들어진다.
ROI 혹은 오브젝트 후보라고 할 수 있는 이 경계박스들은 threshold(0.5)보다 작으면 지워준다. (얅은 경계박스 지워주기)
네트워크 구조는 직선적이다. GoogleLeNet을 약간 변형시켜서 특징 추출기로 사용했다.
이휴 컨볼루션 레이어(C.R) 4회, 풀 커넥션 레이어(FC.R) 2회 하고 사이즈를 7x7x30으로 조정하면 끝난다.
이 마지막 특징 데이터 7x7x30가 바로 예측 결과이며 이 안에 경계박스와 클래스 정보 등 모든 것이 들어있다.
무엇이 들어있는지 자세히 보자.
왼쪽 빨간점으로 표시한 부분을 7X7 그리드 셀 중에 하나로 이미지에서 개의 중앙 부분에 해당한다.
그리고 빨간색 박스보다 큰 노란색 박스가 바로 빨간색 그리드 셀에서 예측한 경계박스이다.
7x7은 영상을 7x7의 격자로 나눈것이다.
30개의 채널은 (경계 박스의 정보 4개(x,y,w,h) , 경계 박스안에 오브젝트가 있을 확률(confidence)) x2, 어떤 클래스일 확률 20개로 구성된다.
경계 박스 정보 x , y : 노란색 경계 박스의 중심이 빨간 격자 셀의 중심에서 어디에 있는가.
경계 박스 정보 w, h : 노란색 경계 박스의 가로 세로 길이가 전체 이미지 크기에 어느 정도 크기를 갖는가
만약 경계 박스가 위의 그림처럼 되었다면 x,y는 모두 0.5정도이고 w,h는 각각 2/7,4/7 정도가 될 것이다.
노란색 경계 박스는 반드시 그 중심이 빨간 그리드 셀 안에 있어야 하며, 가로와 세로 길이는 빨간 그리드 셀보다 작을 수도 있고 그림처럼 클 수도 있다. 또한 정사각형일 필요도 없다.
빨간 그리드 셀 내부 어딘가를 중심으로 하여 근처에 있는 어떤 오브젝트를 둘러싸는 직사각형의 노란색 경계 박스를 그리는 것이 목표이다.
노란색 경계박스가 바로 ROI, 오브젝트 후보이다.
이것을 2개 만든다.
30개의 채널 중에서 앞에 5개는 1번째 경계 박스의 정보가 있으며 다음의 5개에는 2번째 경계 박스의 정보를 가지고 있다.
2번째 경계 박스는 1번째 것과 모양이 비슷할 수도 있고 다를 수도 있다.
위 그림에서는 1번째 경계박스와 다른 모양의 2번 경계박스를 예시로 보여주었다.
30개의 채널의 뒷부분(20)에는 해당 그리드 셀(빨간색 박스)에 오브젝트가 만약 있다면 그것이 어떤 클래스일지에 대한 확률이 저장되어 있다.
각 그리드 셀에는 셀의 주위 혹은 셀 안쪽에 어떤 오브젝트가 있을 거라고 예측한 2개의 경계박스가 있다.
각 경계박스는 오브젝트가 있을 확률(confidence)을 가지고 있다.
이 스칼라 값(숫자 1개)을 그리드 셀의 클래스 분류 확률과 곱하면 경계박스의 클래스 분류 확률을 구할 수 있다.
이것이 위 그림의 긴 노란색 박스이다.
bb1(bound box 1) 즉 첫번째 후보의 경계박스에 대한 클래스 점수표이다.
경계박스의 오브젝트가 있을 확률(confidence)가 매우 낮다면 (0에 가깝다면) 그곳에 어떠한 클래스가 있는지에 대한 정보도 매우 낮아지게 된다.
클래스 첫번째 자리는Dog일 확률이다. dog일 확률을 높은 값부터 낮은 값으로 정렬한다.
여기까지 하면 해당 경계 박스의 클래스가 무엇인지 알 수 있다.
만약 위의 98개의 클래스 점수 표 중에서 97개가 0이고 하나만 0이 아니면 해당 오브젝트가 그 위치에 있다는 것을 간단하게 알 수 있다.
하지만 0이 아닌 노란 박스가 여러개 있을 수 있다.
특히 오브젝트의 크기가 큰 경우 더욱 그러하다.
이것들을 제거하기 위해서 NMS 알고리즘을 사용하여 중복이 되는 경계박스들을 제거하여 오직 하나의 경계 박스만 남긴다.
NMS는 여러 경계 박스들이 겹쳐 있을 때에는 그중에서 최대값을 갖는 하나의 오브젝트만 빼고 나머지를 지운다.(억제한다.)
그러나 여러 경계 박스들이 겹쳐있지 않을때에는 각 경계 박스들은 서로 다른 오브젝트의 경계 박스일 것이라고 생각하고 경계 박스들을 그냥 둔다.
테스트 결과 NMS을 사용하면 mAP 성능이 2-3%상승한다. NMS를 사용하지 않더라도 충분한 성능이 나오므로 NMS가 반드시 필요한 것은 아니라고 한다.
YOLO는 7x7개의 그리드 셀에서 각각 2개의 경계박스 후보를 예측한다.
그러므로 총 98개의 경계박스를 예측한다.
20개의 클래스 중에서 우선 dog만 살펴보자
우선 클래스의 신뢰도 점수가 0.2보다 작은 것은 모두 0으로 셋팅한다. ->첫번째 : threshold 사용
경계 박스의 신뢰도 점수가 어떤 클래스(예를 들어 개)에 대해서 신뢰 점수가 낮다면 그 경계박스 안에 뭐가 있는지는 아직 모르겠지만 최소한 그 클래스(개)는 아닐 것이라고 판단한다.
dog에 대한 두번째 : bbox confidence의 값을 큰것부터 작은것으로 내림차순 정렬하면 위와 같이 1X98크기의 배열을 얻게 된다.
위 그림에서 0.2보다 작은 것은 모두 지웠는데 0.1이 남아있다. 아마 오타이거나 혹은 0.1의 신뢰도가 어느 정도인지 그림으로 보여주기 위함같다. 신뢰도가 0.2보다 작은 것은 모두 지운 후에 개일 활률이 높은 경계박스가 3개 남았다.
개 후보 경계박스 3개를 살펴보자.
세번째 : 두개씩 경계 박스를 비교하여 IOU가 0.5가 넘으면(많이 겹치면) 경계 박스를 없애준다. (NMS)
초록색 경계박스도 개를 어느정도 잘 포착했다.
그러나 개의 다리와 엉덩이 부분은 포착하지 못했기 때문에 오렌지색 경계 박스보다는 나쁘다.
현재 경계박스 신뢰도가 가장 높은 첫번째 값 0.5가 bbox_max이다.
두번째로 높은 신뢰도를 갖는 초록색 경계박스의 값은 원래 0.3이었다.
그런데 두 경계박스의 겹치는 부분이 50%가 넘는다.
이런 경우 둘 중 하나는 중복일 것이라고 판다, 둘 중 신뢰도가 낮은 것을 지워준다.
그래서 0.3의 신뢰도 값을 0으로 설정한다.
개에 대해서 3번째로 높은 신뢰도를 갖는 파란 경계박스는 신뢰도가 가장 높은 오렌지색 경계 박스와 겹치는 부분이 50%가 넘지 않는다.
그렇다면 파란색 경계 박스 안에는 좌측의 개가 아닌 또 다른 개가 있을 수도 있다고 판단한다.
이런 경우는 신뢰도 값을 건드리지 않고 그냥 건너 뛴다.(continue)
지금까지는 개에 대해서만 중복 경계 박스를 지웠다.
개에 대해 정렬한 1X20(첫번째 행)에서는 경계 박스2개(오렌지색과 파란색)만 남고 나머지 18개는 모두 0이 되었다.
이제 남은 19개의 클래스(두번째 행부터 마지막 행까지)에 대해서도 같은 작업을 해준다.
그러면 대부분의 값은 0이 될 것이다.
하지만 아직 한단계가 더 남았다.
사진에서는 개가 1마리 뿐밖에 없었는데 개에 대한 경계 박스가 오렌지색, 파란색 2개가 남아있다.
파란색 경계 박스에는 개가 없었다. 이것을 지워주어야 한다.
bb3은 20개 클래스에 대한 신뢰점수를 가지고 있다.
20개 신뢰점수 중 가장 큰 값을 가지는 클래스가 바로 경계 박스의 컬러이다. ->경계 박스의 클래스 컬러를 정해 그려준다.
만약 가장 큰 값이 0인 경우, 즉 해당 그리드 셀에서의 클래스 신뢰도가 전부 0이라면 bb3에는 오브젝트가 없는 것이다.
그러면 당연히 경계 박스를 그리지 않는다.(skip)
이런 과정을 거쳐서 각 그리도 셀에서는 최댓값을 갖는 클래스 하나와 또 다른 클래스 하나 총 2개가 나타날 수 있다.
만약 한 그리드 셀에서 2개의 클래스가 검출되었다면 오브젝트들이 겹쳐있을 확률이 높을 것이다.
하나의 그리드 셀에서 클래스가 같은 2개의 오브젝트는 나올 수 없는 구조이다.
위의 예에서 개일 확률이 있는 2개의 경계 박스 중에서 오렌지색만 진짜이고 파란색 경계 박스는 잘못된 것이었다.
파란색 경계 박스는 신뢰점수가 0.5이하이므로 나중에 지워진다.
최종적으로 3개의 경계 박스만이 남았다. 경계 박스의 클래스는 컬러로 나타냈다.
학습
S는 격자(grid)의 수를 의미하고 B는 각 그리드 셀이 예측하는 경계 박스의 수이다.(S=7,B=2)
로스 함수를 보면 네트워크를 어떻게 학습시켰는지 파악할 수 있다.
sum-squared error를 사용한 이유는 단지 최적화하기 편해서일 뿐 이것이 평균 정밀도를 최대화하는데 최적의 함수는 아니다.
49개의 그리드셀의 대부분은 오브젝트가 없다. 극단적으로 49개 중에서 1개에만 오브젝트가 나타날 수도 있다.
이 현상으로 인해 각 그리드 셀은 오브젝트가 있을 것 같다는 신뢰점수를 만들어야 하는데, 대부분의 셀에 오브젝트가 없기 때문에 신뢰 점수가 0에 가까워진다.
이 문제를 해결하기 위해서 오브젝트가 있는 경우에 좌표 및 클래스 예측 로스는 키우고, 오브젝트가 없는 경우는 로스를 줄였다.
그것이
=5 ,
=0.5이다.
오브젝트가 있는 경우에만 학습을 제대로 하라고 로스를 5배 키우고 오브젝트가 없는 경우는 로스를 반으로 줄인다.
로 오브젝트가 있는 셀과 없는 셀을 구분한다.
는 오브젝트가 있는 그리드셀 i이다. 경계 박스와는 관계 없다.
는 그리드셀 i에 있는 j번째 경계 박스가 예측한 것으로 예측에 대한 책임을 져야 한다.
이렇게 하면 오브젝트가 있는 그리드셀 i 에서만 로스가 발생하며 오브젝트가 없는 그리드셀들에서는 loss계산을 하지 않는다.
경계 박스 예측기들은 해당 셀에 오브젝츠가 있을 경우에만 잘 예측하면 된다.
총 5종류의 로스를 계산한다.
1th : 경계 박스의 x, y 좌표 학습하기
- 실제로 오브젝트가 i 에 있을 때 그리드셀i 에서 예측한 경계박스j 가 정답과 같도록 학습한다.
- 그리드셀이 예측하는 2개의 경계 박스(j=0, j=1) 모두 정답과 같아지도록 유도한다.
2th : 경계 박스의 width, height 학습하기
- 첫번째와 동일한데 단지 루트를 씌워서 사용한 것만 다르다.
큰 경계박스에서는 width, height 를 조금만 키워도 넓이가 확 증가한다. 미분값이 크다.
작은 경계 박스에서는 w,h 를 많이 키워도 넓이의 변화가 크지 않다. 미분값이 작다.
sum-squared error 를 사용하면 박스가 큰것과 작은것의 미분 차이가 크게 나기 때문에 이를 반영하기 위해 루트를 사용했다.
3th : 그리드 셀 i 에 오브젝트가 있을 경우 클래스 예측하기
- 가장 평범한 로스이다. 이 오브젝트가 뭔지 예측해라
4th : 그리드 셀 i 에 오브젝트가 없을 경우 클래스 예측하기
- 3th 에 비해 가중치가 0.5 이다. 그러므로 3th 이 2배 더 중요하다.
오브젝트가 없는 그리드셀에서는 클래스 분류 정확도가 좀 낮아도 괜찮다. 어차피 배경이니까, 배경일 확률만 다른것보다 좀 더 높으면 된다.
가중치가 낮으므로 오브젝트가 있는 셀(3th) 에서는 더 정확히 클래스 분류 하게 된다.
5th : 여기에는 B 에 대한 Sum 이 없다. 각 그리드셀 i 에서 경계박스는 2번(B=2) 예측하지만 클래스 확률 c(20종류) 는 공유하기 때문이다.
위의 2줄은 좌표(coordinate) 부분을 학습하기 위한 것이다.
S는 격자의 수를 의미하고 B는 각 그리드셀이 예측하는 경계박스의 수이다.
7X7=49개의 그리드 셀이 경계박스를 2개씩 예측하므로 2중 for문 형태이다.
해당 셀에 오브젝트가 있을 때만 로스를 구해서 최적화한다.
셀에 오브젝트가 없는 경우에는 좌표 예측이 무엇이든 상관 없다.
coordError = 0
for ( i = 0 ; i < S*S < i++){ // 7 * 7
for( j = 0 ; j < B < j++){ // 2
if(해당 셀에 진짜로 오브젝트가 있으면){
coordError += ... // 에러다. 학습을 통해 에러를 줄여 나간다.
}
else{
//해당 셀에 오브젝트가 없으면 신경쓰지 않는다.
}
}
}
[출처] YOLO, Object Detection Network |작성자 sogangori
'Programmer > Deep Learning' 카테고리의 다른 글
| [논문리뷰]DeepFace: Closing the Gap to Human-Level Performance in Face Verification (0) | 2020.07.02 |
|---|---|
| [논문리뷰] Deep Residual Learning for Image Recognition (0) | 2020.05.03 |
| [논문리뷰] Histograms of Oriented Gradients for Human Detection (0) | 2020.04.28 |
| YOLO 튜토리얼 3. Implementing the forward pass of the network (0) | 2020.04.26 |
| YOLO 튜토리얼 2. Creating the layers of the network architecture (0) | 2020.04.26 |